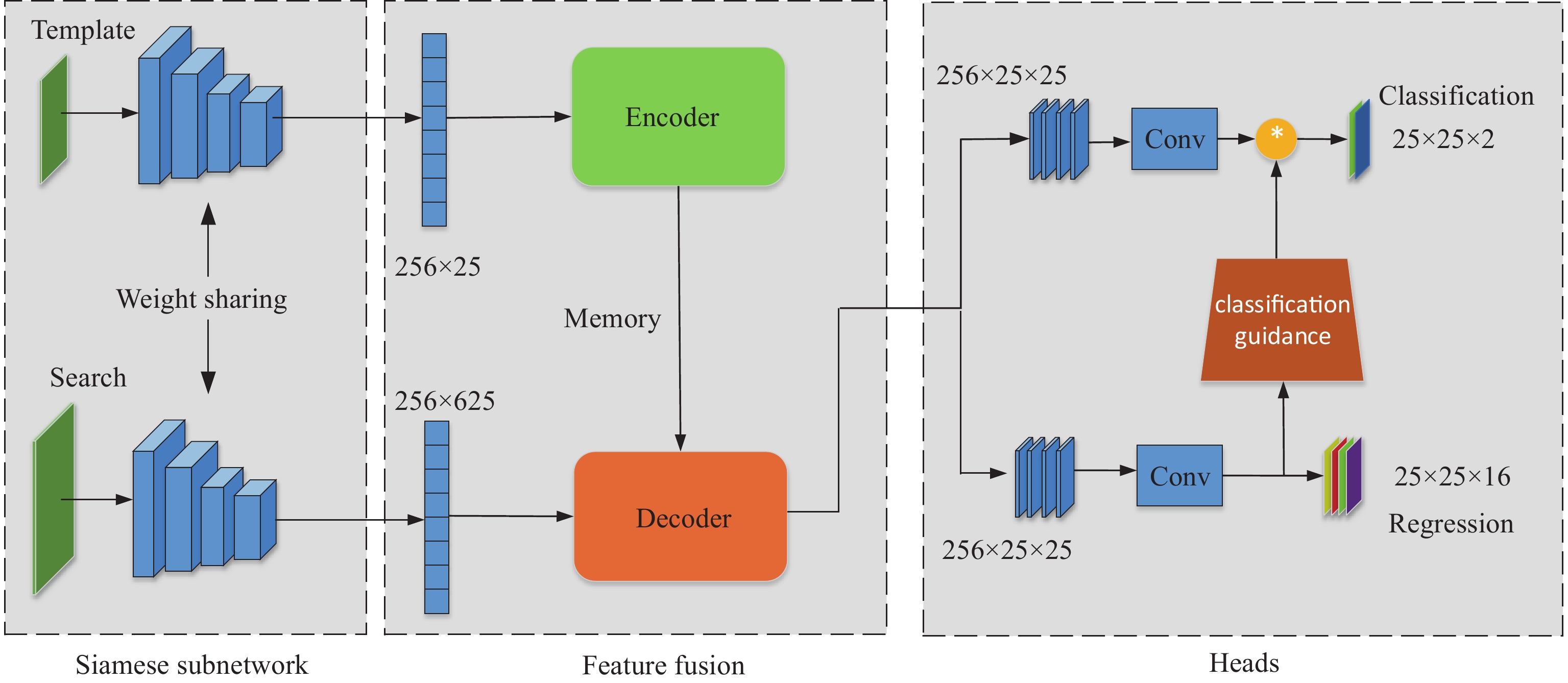
The general paradigm of traditional Siamese networks involves using cross-correlations to fuse features from the backbone, and this paradigm is limited by the inductive bias of the convolution kernel, resulting in the lack of global information. In this paper, we propose the Siamese learning regression distribution (SiamLRD) to address the local limitations of traditional cross-correlation operations on feature fusion and weak self-connections between features within different branches. The SiamLRD uses the cross-attention mechanism to replace cross-correlations between the features of the target region of interest and the template so as to enhance flexibility. Firstly, the original transformer structure is improved to be suitable for convolutional Siamese networks. The improved transformer architecture is then used to replace cross-correlation operations, resulting in more comprehensive feature fusion between branches. Secondly, we introduce a new decoder structure into the novel fusion strategy to enhance the correlation between classification scores and regression accuracy during decoding. Multiple benchmarks are used to test the proposed SiamLRD approach, and it is verified that the proposed approach improves the baseline with 5.8% in terms of AO and 9.7% in terms of SR0.75 on the GOT-10K dataset.
- Open Access
- Article
Learning Regression Distribution: Information Diffusion from Template to Search for Visual Object Tracking
- Shuo Hu *,
- Jinbo Lu,
- Sien Zhou
Author Information
Received: 05 Jul 2023 | Accepted: 19 Oct 2023 | Published: 26 Mar 2024
Abstract
Graphical Abstract
References
- 1.Bertinetto, L.; Valmadre, J.; Henriques, J. F.;
et al . Fully-convolutional siamese networks for object tracking. InProceedings of European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016 ; Springer: Berlin/Heidelberg, 2016; pp. 850–865. doi: 10.1007/978-3-319-48881-3_56 - 2.Li, B.; Yan, J. J.; Wu, W.;
et al . High performance visual tracking with siamese region proposal network. InProceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018 ; IEEE: New York, 2018; pp. 8971–8980. doi: 10.1109/CVPR.2018.00935 - 3.Li, B.; Wu, W.; Wang, Q.;
et al . SiamRPN++: Evolution of siamese visual tracking with very deep networks. InProceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019 ; IEEE: New York, 2019; pp. 4277–4286. doi: 10.1109/CVPR.2019.00441 - 4.Chen, Z. D.; Zhong, B. N.; Li, G. R.;
et al . Siamese box adaptive network for visual tracking. InProceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13 –19 June 2020 ; IEEE: New York, 2020; pp. 6667–6676. doi: 10.1109/CVPR42600.2020.00670 - 5.Guo, D. Y.; Wang, J.; Cui, Y.;
et al . SiamCAR: Siamese fully convolutional classification and regression for visual tracking. InProceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020 ; IEEE: New York, 2020; pp. 6268–6276. doi: 10.1109/CVPR42600.2020.00630 - 6.Guo, D. Y.; Shao, Y. Y.; Cui, Y.;
et al . Graph attention tracking. InProceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021 ; IEEE: New York, 2021; pp. 9538–9547. doi: 10.1109/CVPR46437.2021.00942 - 7.Yu, Y. C.; Xiong, Y. L.; Huang, W. L.;
et al . Deformable Siamese attention networks for visual object tracking. InProceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020 ; IEEE: New York, 2020; pp. 6727–6736. doi: 10.1109/CVPR42600.2020.00676 - 8.Zhao, M. J.; Okada, K.; Inaba, M. TrTr: Visual tracking with transformer. arXiv: 2105.03817, 2021. doi: 10.48550/arXiv.2105.03817
- 9.Carion, N.; Massa, F.; Synnaeve, G.;
et al . End-to-end object detection with transformers. InProceedings of the 16th European Conference on Computer Vision ,Glasgow ,UK ,23–28 August 2020 ; Springer: Berlin/Heidelberg, 2020; pp. 213–229. doi: 10.1007/978-3-030-58452-8_13 - 10.Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.;
et al . An Image is worth 16x16 words: Transformers for image recognition at scale. InProceedings of the 9th International Conference on Learning Representations, 3 –7 May 2021 ; OpenReview. net, 2021. - 11.Vaswani, A.; Shazeer, N.; Parmar, N.;
et al . Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach ,CA ,USA, 04 December 2017 ; Curran Associates Inc. : Red Hook, 2017; pp. 6000–6010. doi: 10.5555/3295222.3295349 - 12.Xiong, R. B.; Yang, Y. C.; He, D.;
et al . On layer normalization in the transformer architecture. InProceedings of the 37th International Conference on Machine Learning ,13 July 2020 ; PMLR, 2020; p. 975. - 13.He, K. M.; Zhang, X. Y.; Ren, S. Q.;
et al . Deep residual learning for image recognition. InProceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition ,Las Vegas ,NV ,USA ,27 –30 June 2016 ; IEEE: New York, 2016; pp. 770–778. doi: 10.1109/CVPR.2016.90 - 14.Bhat, G.; Danelljan, M.; van Gool, L.;
et al . Learning discriminative model prediction for tracking. InProceedings of 2019 IEEE/CVF International Conference on Computer Vision ,Seoul ,Korea (South ),27 October 2019–02 November 2019 ; IEEE: New York, 2019, pp. 6181–6190. doi: 10.1109/ICCV.2019.00628 - 15.Wang, N.; Zhou, W. G.; Wang, J.;
et al . Transformer meets tracker: Exploiting temporal context for robust visual tracking. InProceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Nashville, TN, USA, 20–25 June 2021 ; IEEE: New York, 2021, pp. 1571–1580. doi: 10.1109/CVPR46437.2021.00162 - 16.Szegedy, C.; Liu, W.; Jia, Y. Q.;
et al . Going deeper with convolutions. InProceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition ,Boston ,MA ,USA ,07–12 June 2015 ; IEEE: New York, 2015; pp. 1–9. doi: 10.1109/CVPR.2015.7298594 - 17.Kingma, D. P.; Ba, J. Adam: A method for stochastic optimization. In
Proceedings of the 3rd International Conference on Learning Representations ,San Diego ,CA ,USA ,7 –9 May 2015 ; ICLR, 2015. - 18.Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv: 1711.05101, 2019. doi: 10.48550/arXiv.1711.05101
- 19.Li, X.; Lv, C. Q.; Wang, W. H.; et al. Generalized focal loss: Towards efficient representation learning for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell., 2023, 45: 3139−3153. doi: 10.1109/TPAMI.2022.3180392
- 20.Rezatofighi, H.; Tsoi, N.; Gwak, J. Y.;
et al . Generalized intersection over union: A metric and a loss for bounding box regression. InProceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Long Beach ,CA ,USA ,15–20 June 2019 ; IEEE: New York, 2019; pp. 658–666. doi: 10.1109/CVPR.2019.00075 - 21.Jiang, B. R.; Luo, R. X.; Mao, J. Y.;
et al . Acquisition of localization confidence for accurate object detection. InProceedings of the 15th European Conference on Computer Vision ,Munich ,Germany ,8–14 September 2018 ; Springer: Berlin/Heidelberg, 2018; pp. 816–832. doi: 10.1007/978-3-030-01264-9_48 - 22.Li, X.; Wang, W. H.; Hu, X. L.;
et al . Generalized focal loss V2: Learning reliable localization quality estimation for dense object detection. InProceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Nashville ,TN ,USA ,20–25 June 2021 ; IEEE: New York, 2021; pp. 11627–11636. doi: 10.1109/CVPR46437.2021.01146 - 23.Huang, L. H.; Zhao, X.; Huang, K. Q. GOT-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell., 2021, 43: 1562−1577. doi: 10.1109/TPAMI.2019.2957464
- 24.Fan, H.; Lin, L. T.; Yang, F.;
et al . LaSOT: A high-quality benchmark for large-scale single object tracking. InProceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Long Beach ,CA ,USA ,15–20 June 2019 ; IEEE: New York, 2019; pp. 5369–5378. doi: 10.1109/CVPR.2019.00552 - 25.Zhu, Z.; Wang, Q.; Li, B.;
et al . Distractor-aware Siamese networks for visual object tracking. InProceedings of the 15th European Conference on Computer Vision ,Munich ,Germany ,8–14 September 2018 ; Springer: Berlin/Heidelberg, 2018; pp. 103–119. doi: 10.1007/978-3-030-01240-3_7 - 26.Wang, G. T.; Luo, C.; Xiong, Z. W.;
et al . SPM-tracker: Series-parallel matching for real-time visual object tracking. InProceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Long Beach ,CA ,USA ,15–20 June 2019 ; IEEE: New York, 2019, pp. 3638–3647. doi: 10.1109/CVPR.2019.00376 - 27.Xu, Y. D.; Wang, Z. Y.; Li, Z. X.;
et al . SiamFC++: Towards robust and accurate visual tracking with target estimation guidelines. InProceedings of the 34th AAAI Conference on Artificial Intelligence ,New York ,NY ,USA ,7 –12 February 2020 ; AAAI: Palo Alto, 2020; pp. 12549–12556. doi: 10.1609/aaai.v34i07.6944 - 28.Danelljan, M.; Bhat, G.; Khan, F. S.;
et al . ATOM: Accurate tracking by overlap maximization. InProceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Long Beach ,CA ,USA ,15 –20 June 2019 ; IEEE: New York, 2019; pp. 4655–4664. doi: 10.1109/CVPR.2019.00479 - 29.Hu, S.; Zhou, S. E.; Lu, J. B.;
et al . Flexible dual-branch Siamese network: Learning location quality estimation and regression distribution for visual tracking.IEEE Trans. Comput. Soc. Syst. 2023 , in press. doi: 10.1109/TCSS.2023.3235649 - 30.Zheng, L. Y.; Tang, M.; Chen, Y. Y.;
et al . Learning feature embeddings for discriminant model based tracking. arXiv: 1906.10414, 2020. doi: 10.48550/arXiv.1906.10414 - 31.Danelljan, M.; van Gool, L.; Timofte, R. Probabilistic regression for visual tracking. In
Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Seattle ,WA ,USA ,13 –19 June 2020 ; IEEE: New York, 2020; pp. 7181–7190. doi: 10.1109/CVPR42600.2020.00721 - 32.Zhang, J. P.; Dai, K. H.; Li, Z. W.; et al. Spatio-temporal matching for Siamese visual tracking. Neurocomputing, 2023, 522: 73−88. doi: 10.1016/j.neucom.2022.11.093
- 33.Kim, M.; Lee, S.; Ok, J.;
et al . Towards sequence-level training for visual tracking. InProceedings of the 17th European Conference on Computer Vision ,Tel Aviv ,Israel ,23–27 October ,2022 ; Springer: Berlin/Heidelberg, 2022, pp. 534–551. doi: 10.1007/978-3-031-20047-2_31 - 34.L i, J. F.; Li, B.; Ding, G. D.; et al. Siamese global location-aware network for visual object tracking. Int. J. Mach. Learn. Cybern., 2023, 14: 3607−3620. doi: 10.1007/s13042-023-01853-2 doi: 10.1007/s13042-023-01853-2
- 35.Dai, K. N.; Zhang, Y. H.; Wang, D.;
et al . High-performance long-term tracking with meta-updater. InProceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Seattle ,WA ,USA ,13 –19 June 2020 ; IEEE: New York, 2020; pp. 6297–6306. doi: 10.1109/CVPR42600.2020.00633 - 36.Huang, L. H.; Zhao, X.; Huang, K. Q. GlobalTrack: A simple and strong baseline for long-term tracking. In
Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence ,New York ,NY ,USA ,7–12 February 2020 ; AAAI: Palo Alto, 2019; pp. 11037–11044. doi: 10.1609/aaai.v34i07.6758 - 37.Danelljan, M.; Bhat, G.; Khan, F. S.;
et al . ECO: Efficient convolution operators for tracking. InProceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition ,Honolulu ,HI ,USA ,21 –26 July 2017 ; IEEE: New York, 2017; pp. 6931–6939. doi: 10.1109/CVPR.2017.733 - 38.Zhang, Z. P.; Peng, H. W. Deeper and wider Siamese networks for real-time visual tracking. In
Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Long Beach ,CA ,USA ,15 –20 June 2019 ; IEEE: New York, 2019; pp. 4586–4595. doi: 10.1109/CVPR.2019.00472 - 39.Song, Y. B.; Ma, C.; Wu, X. H.;
et al . VITAL: VIsual tracking via adversarial learning. InProceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Salt Lake City ,UT ,USA ,18 –23 June 2018 ; IEEE: New York, 2018; pp. 8990–8999. doi: 10.1109/CVPR.2018.00937 - 40.Fan, H.; Ling, H. B. Siamese cascaded region proposal networks for real-time visual tracking. In
Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition ,Long Beach ,CA ,USA ,15–20 June 2019 ; IEEE: New York, 2018; pp. 7944–7953. doi: 10.1109/CVPR.2019.00814 - 41.Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In
Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition ,Las Vegas ,NV ,USA ,27–30 June 2016 ; IEEE: New York, 2016; pp. 4293–4302. doi: 10.1109/CVPR.2016.465 - 42.Xu, T. Y.; Feng, Z. H.; Wu, X. J.;
et al . Joint group feature selection and discriminative filter learning for robust visual object tracking. InProceedings of 2019 IEEE/CVF International Conference on Computer Vision ,Seoul ,Korea (South ),27 October 2019–02 November 2019 ; IEEE: New York, 2019; pp. 7949–7959. doi: 10.1109/ICCV.2019.00804 - 43.Hu, W. M.; Wang, Q.; Zhang, L.; et al. SiamMask: A framework for fast online object tracking and segmentation. IEEE Trans. Pattern Anal. Mach. Intell., 2023, 45: 3072−3089. doi: 10.1109/TPAMI.2022.3172932

How to Cite
Hu, S.; Lu, J.; Zhou, S. Learning Regression Distribution: Information Diffusion from Template to Search for Visual Object Tracking. International Journal of Network Dynamics and Intelligence 2024, 3 (1), 100006. https://doi.org/10.53941/ijndi.2024.100006.
RIS
BibTex
Copyright & License

Copyright (c) 2024 by the authors.
This work is licensed under a Creative Commons Attribution 4.0 International License.
Contents
References
 Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia
Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia General Inquiries: info@sciltp.com
General Inquiries: info@sciltp.com