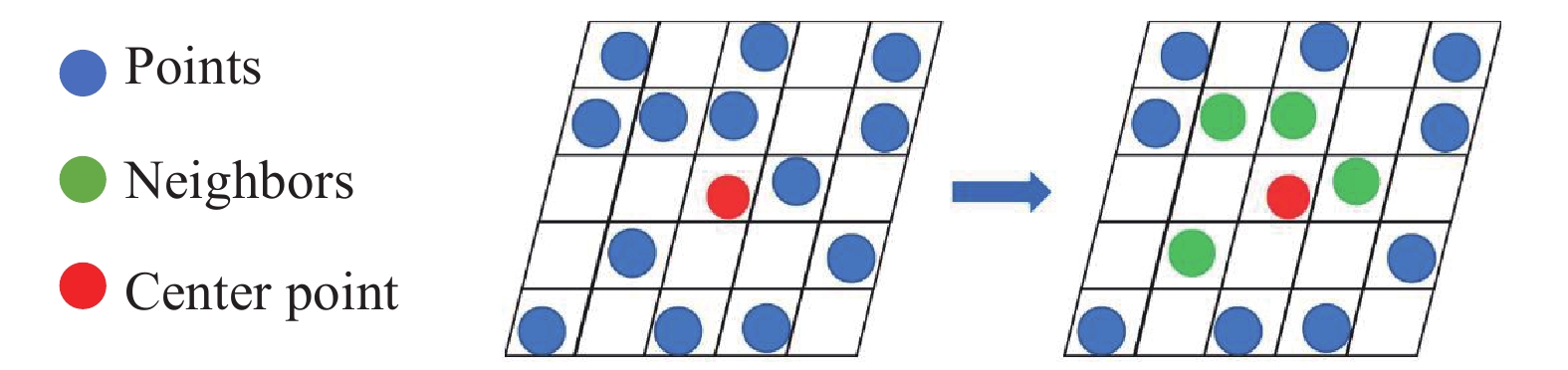
The deep learning methods achieve good results in the semantic segmentation and classification of the 3D point clouds. The popular convolutional neural networks illustrate the importance of using the neighboring information of the points. Searching the neighboring points is an important process that can get the context information of each point. The K-nearest neighbor (KNN) search and ball query methods are usually used to find the neighboring points, but a long time is required to construct the KD-tree and calculate the Euclidean distance. In this work, we introduce a fast approach (called the voxel search) to finding the neighbors, where the key is to use the voxel coordinates to search the neighbors directly. However, it is difficult to apply this method directly to the general network structure such as the U-net. In order to improve its applicability, the corresponding up-sampling and down-sampling methods are proposed. Additionally, we propose a fast search structure network (FSS-net) which consists of the feature extraction layer and the sampling layer. In order to demonstrate the effectiveness of the FSS-net, we conduct experiments on a single object in both indoor and outdoor environments. The speed of the voxel search approach is compared with that of the KNN and ball query. The experimental results show that our method is faster and can be directly applied to any point-based deep learning networks.
- Open Access
- Article
FSS-Net: A Fast Search Structure for 3D Point Clouds in Deep Learning
- Jiawei Wang 1,
- Yan Zhuang 1, *,
- Yisha Liu 2, *
Author Information
Received: 22 Feb 2023 | Accepted: 05 May 2023 | Published: 23 Jun 2023
Abstract
Graphical Abstract
References
- 1.Qi, R.Q.; Su, H.; Kaichun, M.; et al. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, 2017; pp. 77–85. doi: 10.1109/CVPR.2017.16
- 2.Zhang, J.Z.; Zhu, C.Y.; Zheng, L.T.; et al. Fusion-aware point convolution for online semantic 3D scene segmentation. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, 2020; pp. 4533–4542. doi: 10.1109/CVPR42600.2020.00459
- 3.Zhang, C.J.; Xu, S.H.; Jiang, T.; et al. Integrating normal vector features into an atrous convolution residual network for LiDAR point cloud classification. Remote Sen., 2021, 13: 3427.
- 4.Wang, Y.; Sun, Y.B.; Liu, Z.W.; et al. Dynamic graph CNN for learning on point clouds. ACM Trans. Graphics, 2019, 38: 146.
- 5.Yan, X.; Zheng, C.D.; Li, Z.; et al. PointASNL: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, 2020; pp. 5588–5597. doi: 10.1109/CVPR42600.2020.00563
- 6.Wu, W.X.; Qi, Z.A.; Li, F.X. PointConv: Deep convolutional networks on 3D point clouds. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, 2019; pp. 9613–9622. doi: 10.1109/CVPR.2019.00985
- 7.Woo, S.; Lee, D.; Lee, J.; et al. CKConv: Learning feature voxelization for point cloud analysis. arXiv: 2107.12655, 2021. doi: 10.48550/arXiv.2107.12655
- 8.Thomas, H.; Qi, C.R.; Deschaud, J.E.; et al. KPConv: Flexible and deformable convolution for point clouds. In Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October 2019 - 02 November 2019; IEEE: New York, 2019; pp. 6410–6419. doi: 10.1109/ICCV.2019.00651
- 9.Qi, C.R.; Yi, L.; Su, H.; et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California, USA, 4–9 December 2017; Curran Associates Inc: Red Hook, 2017; pp. 5105–5114.
- 10.Pham, Q.H.; Nguyen, T.; Hua, B.S.; et al. JSIS3D: Joint semantic-instance segmentation of 3D point clouds with multi-task pointwise networks and multi-value conditional random fields. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, 2019; pp. 8819–8828. doi: 10.1109/CVPR.2019.00903
- 11.Lei, H.; Akhtar, N.; Mian, A. Octree guided CNN with spherical kernels for 3D point clouds. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, 2019; pp. 9623–9632. doi: 10.1109/CVPR.2019.00986
- 12.Hu, Q.Y.; Yang, B.; Xie, L.H.; et al. RandLA-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, 2020; pp. 11105–11114. doi: 10.1109/CVPR42600.2020.01112
- 13.Engelmann, F.; Bokeloh, M.; Fathi, A.; et al. 3D-MPA: Multi-proposal aggregation for 3D semantic instance segmentation. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, 2020; pp. 9028–9037. doi: 10.1109/CVPR42600.2020.00905
- 14.Atzmon, M.; Maron, H.; Lipman, Y. Point convolutional neural networks by extension operators. ACM Trans. Graphics, 2018, 37: 71.
- 15.Eldar, Y.; Lindenbaum, M.; Porat, M.; et al. The farthest point strategy for progressive image sampling. IEEE Trans. Image Process., 1997, 6: 1305−1315.
- 16.Li, J.; Chen, B.M.; Lee, G.H. SO-Net: Self-organizing network for point cloud analysis. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, 2018; pp. 9397–9406. doi: 10.1109/CVPR.2018.00979
- 17.Maturana, D.; Scherer, S. VoxNet: A 3D convolutional neural network for real-time object recognition. In Proceedings of 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September 2015–02 October 2015; IEEE: New York, 2015; pp. 922–928. doi: 10.1109/IROS.2015.7353481
- 18.Qi, C.R.; Su, H.; Nießner, M.; et al. Volumetric and multi-view CNNs for object classification on 3D data. In Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, 2016; pp. 5648–5656. doi: 10.1109/CVPR.2016.609
- 19.Riegler, G.; Osman Ulusoy, A.; Geiger, A. OctNet: Learning deep 3D representations at high resolutions. In Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, 2017; pp. 6620–6629. doi: 10.1109/CVPR.2017.701
- 20.Rethage, D.; Wald, J.; Sturm, J.; et al. Fully-convolutional point networks for large-scale point clouds. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, 2018; pp. 625–640. doi: 10.1007/978-3-030-01225-0_37
- 21.Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3D object detection. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, 2018; pp. 4490–4499. doi: 10.1109/CVPR.2018.00472
- 22.Zhang, Y.; Zhou, Z.X.; David, P.; et al. PolarNet: An improved grid representation for online LiDAR point clouds semantic segmentation. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, 2020; pp. 9598–9607. doi: 10.1109/CVPR42600.2020.00962
- 23.Zhang, W.; Xiao, C.X. PCAN: 3D attention map learning using contextual information for point cloud based retrieval. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, 2019; pp. 12428–12437. doi: 10.1109/CVPR.2019.01272
- 24.Choy, C.; Gwak, J.Y.; Savarese, S. 4D spatio-temporal ConvNets: Minkowski convolutional neural networks. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, 2019; pp. 3070–3079. doi: 10.1109/CVPR.2019.00319
- 25.Cheng, R.; Razani, R.; Taghavi, E.; et al. (AF)2-S3Net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: New York, 2021; pp. 12542–12551. doi: 10.1109/CVPR46437.2021.01236
- 26.Wang, Z.; Lu, F. VoxSegNet: Volumetric CNNs for semantic part segmentation of 3D shapes. IEEE Trans. Vis. Comput. Graph., 2020, 26: 2919−2930.
- 27.Liu, Z.J.; Tang, H.T.; Lin, Y.J.; et al. Point-voxel CNN for efficient 3D deep learning. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc: Red Hook, 2019; p. 87.
- 28.Tang, H.T.; Liu, Z.J.; Zhao, S.Y.; et al. Searching efficient 3D architectures with sparse point-voxel convolution. In Proceedings of 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, 2020; pp. 685–702. doi: 10.1007/978-3-030-58604-1_41
- 29.Xu, J.Y.; Zhang, R.X.; Dou, J.; et al. RPVNet: A deep and efficient range-point-voxel fusion network for LiDAR point cloud segmentation. In Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE: New York, 2021; pp. 16004–16013. doi: 10.1109/ICCV48922.2021.01572
- 30.Zhu, X.G.; Zhou, H.; Wang, T.; et al. Cylindrical and asymmetrical 3D convolution networks for LiDAR-based perception. IEEE Trans. Pattern Anal. Mach. Intell., 2022, 44: 6807−6822.
- 31.Li, Y.Y.; Bu, R.; Sun, M.C.; et al. PointCNN: Convolution on X-transformed points. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 3–8 December 2018; Curran Associates Inc: Red Hook, 2018; pp. 828–838.
- 32.Liu, Y.C.; Fan, B.; Xiang, S.M.; et al. Relation-shape convolutional neural network for point cloud analysis. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; 2019; pp. 8887–8896. doi: 10.1109/CVPR.2019.00910
- 33.Wang, C.; Samari, B.; Siddiqi, K. Local spectral graph convolution for point set feature learning. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, 2018; pp. 56–71. doi: 10.1007/978-3-030-01225-0_4
- 34.Klokov, R.; Lempitsky, V. Escape from cells: Deep Kd-networks for the recognition of 3D point cloud models. In Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: New York, 2017; pp. 863–872. doi: 10.1109/ICCV.2017.99
- 35.Armeni, I.; Sax, S.; Zamir, A.R.; et al. Joint 2D-3D-semantic data for indoor scene understanding. arXiv: 1702.01105, 2017. doi: 10.48550/arXiv.1702.01105
- 36.Behley, J.; Garbade, M.; Milioto, A.; et al. SemanticKITTI: A dataset for semantic scene understanding of LiDAR sequences. In Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October 2019 - 02 November 2019; IEEE: New York, 2019; pp. 9296–9306. doi: 10.1109/ICCV.2019.00939
- 37.Shen, Y.; Feng, C.; Yang, Y.Q.; et al. Mining point cloud local structures by kernel correlation and graph pooling. In Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, 2018; pp. 4548–4557. doi: 10.1109/CVPR.2018.00478
- 38.Tchapmi, L.; Choy, C.; Armeni, I.; et al. SEGCloud: Semantic segmentation of 3D point clouds. In Proceedings of 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: New York, 2017; pp. 537–547. doi: 10.1109/3DV.2017.00067
- 39.Zhang, C.; Luo, W.J.; Urtasun, R. Efficient convolutions for real-time semantic segmentation of 3D point clouds. In Proceedings of 2018 International Conference on 3D Vision (3DV), Verona, Italy, 05–08 September 2018; IEEE: New York, 2018; pp. 399–408. doi: 10.1109/3DV.2018.00053
- 40.Zhao, H.S.; Jiang, L.; Fu, C.W.; et al. PointWeb: Enhancing local neighborhood features for point cloud processing. In Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; 2019; pp. 5560–5568. doi: 10.1109/CVPR.2019.00571
- 41.Lin, Y.Q.; Yan, Z.Z.; Huang, H.B.; et al. FPConv: Learning local flattening for point convolution. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: New York, 2020; pp. 4292–4301. doi: 10.1109/CVPR42600.2020.00435
- 42.Kochanov, D.; Nejadasl, F.K.; Booij, O. KPRNet: Improving projection-based LiDAR semantic segmentation. arXiv: 2007.12668, 2020. doi: 10.48550/arXiv.2007.12668

How to Cite
Wang, J.; Zhuang, Y.; Liu, Y. FSS-Net: A Fast Search Structure for 3D Point Clouds in Deep Learning. International Journal of Network Dynamics and Intelligence 2023, 2 (2), 100005. https://doi.org/10.53941/ijndi.2023.100005.
RIS
BibTex
Copyright & License

Copyright (c) 2023 by the authors.
This work is licensed under a Creative Commons Attribution 4.0 International License.
Contents
References
 Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia
Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia General Inquiries: info@sciltp.com
General Inquiries: info@sciltp.com