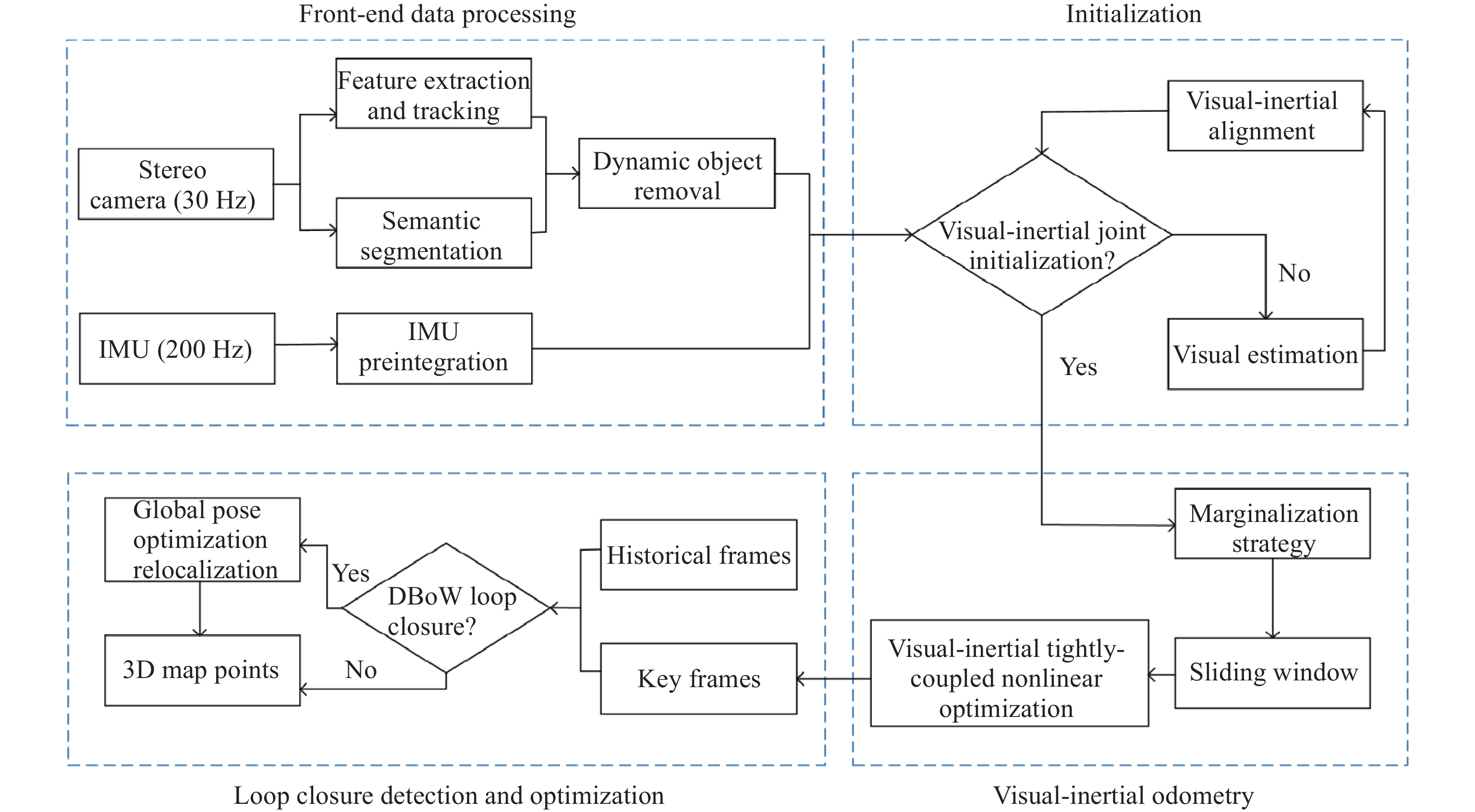
A simultaneous localization and mapping (SLAM) system is presented in this paper based on visual-inertial fusion to solve the pose estimation drift problem caused by weak texture environments or rapid robot movements. The camera and inertial measurement unit (IMU) is initialized through IMU pre-integration and visual front-end processing, and a tightly coupled residual function model is employed in the back-end to eliminate accumulated errors. To realize the real-time pose estimation in the complex loop scene, the sliding window optimization method based on the marginalization strategy is adopted to improve the optimization efficiency of the system, and the loop detection algorithm based on the bag-of-words model is exploited to solve the cumulative error problem generated during long-term operation. Furthermore, because of the interference (of complex scenes with dynamic targets) in system modeling and localization of the environment, this paper introduces a deep-learning semantic segmentation model to segment and eliminate dynamic targets. The system performance test is carried out based on the EuRoC dataset and the KITTI dataset. Finally, the experimental results illustrate that the proposed method has improved system robustness and localization accuracy compared with the pure vision algorithm and the visual-inertial fusion algorithm without removing dynamic targets.
- Open Access
- Article
Localization and Mapping Method Based on Multimodal Information Fusion and Deep Learning for Dynamic Object Removal
- Chong Ma,
- Peng Cheng,
- Chenxiao Cai *
Author Information
Received: 10 Sep 2023 | Accepted: 25 Dec 2023 | Published: 26 Jun 2024
Abstract
Graphical Abstract
Keywords
visual-inertial system | loop detection | sliding window | deep learning | dynamic targets
References
- 1.Macario Barros, A.; Michel, M.; Moline, Y.; et al. A comprehensive survey of visual SLAM algorithms. Robotics, 2022, 11: 24. doi: 10.3390/robotics11010024
- 2.Zheng, S.R.; Wang, J.L.; Rizos, C.; et al. Simultaneous Localization and Mapping (SLAM) for autonomous driving: Concept and analysis. Remote Sens., 2023, 15: 1156. doi: 10.3390/rs15041156
- 3.Davison, A.J.; Reid, I.D.; Molton, N.D.; et al. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell., 2007, 29: 1052−1067. doi: 10.1109/TPAMI.2007.1049
- 4.Schöps, T.; Sattler, T.; Pollefeys, M. BAD SLAM: Bundle adjusted direct RGB-D SLAM. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019 ; IEEE: New York, 2019; pp. 134–144. doi:10.1109/CVPR.2019.00022 - 5.Shu, F.W.; Wang, J.X.; Pagani, A.;
et al . Structure PLP-SLAM: Efficient sparse mapping and localization using point, line and plane for monocular, RGB-D and stereo cameras. InProceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023 ; IEEE: New York, 2023; pp. 2105–2112. doi:10.1109/ICRA48891.2023.10160452 - 6.Guo, R.F.; Jia, R. Research on multi-information fusion target tracking algorithm based on LK optical flow method. Mod. Electron. Tech., 2019, 42: 55−59. doi: 10.16652/j.issn.1004-373x.2019.18.013
- 7.Guan, Y.F. Research on Positioning Technology Combining Binocular Vision and Inertial Measurement Unit. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2020. doi:10.27061/d.cnki.ghgdu.2020.003647 (In Chinese)
- 8.Mei, X.; Sun, X.; Zhou, M.C.;
et al . On building an accurate stereo matching system on graphics hardware. InProceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011 ; IEEE: New York, 2011; pp. 467–474. doi:10.1109/ICCVW.2011.6130280 - 9.Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision, 2004, 60: 91−110. doi: 10.1023/B:VISI.0000029664.99615.94
- 10.Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In
Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006 ; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. doi:10.1007/11744023_32 - 11.Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In
Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006 ; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. doi:10.1007/11744023_34 - 12.Rublee, E.; Rabaud, V.; Konolige, K.;
et al . ORB: An efficient alternative to SIFT or SURF. InProceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011 ; IEEE: New York, 2011; pp. 2564–2571. doi:10.1109/ICCV.2011.6126544 - 13.Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv., 2019, 51: 37. doi: 10.1145/3177853
- 14.Beghdadi, A.; Mallem, M. A comprehensive overview of dynamic visual SLAM and deep learning: Concepts, methods and challenges. Mach. Vision Appl., 2022, 33: 54. doi: 10.1007/s00138-022-01306-w
- 15.Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM, 1981, 24: 381−395. doi: 10.1145/358669.358692
- 16.Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Rob., 2015, 31: 1147−1163. doi: 10.1109/TRO.2015.2463671
- 17.Chen, L.C.; Papandreou, G.; Schroff, F.;
et al . Rethinking atrous convolution for semantic image segmentation. arXiv: 1706.05587, 2017. - 18.Hajebi, K.; Abbasi-Yadkori, Y.; Shahbazi, H.;
et al . Fast approximate nearest-neighbor search withk -nearest neighbor graph. InProceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16 July 2011 ; AAAI Press: Palo Alto, 2011; pp. 1312–1317. doi:10.5555/2283516.2283615 - 19.Szegedy, C.; Ioffe, S.; Vanhoucke, V.;
et al . Inception-v4, Inception-ResNET and the impact of residual connections on learning. InProceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, USA, 4 February 2017 ; AAAI Press: Palo Alto, 2017; pp. 4278–4284. doi:10.5555/3298023.3298188 - 20.Gao, X.S.; Hou, X.R.; Tang, J.L.; et al. Complete solution classification for the perspective-three-point problem. IEEE Trans. Pattern Anal. Mach. Intell., 2003, 25: 930−943. doi: 10.1109/TPAMI.2003.1217599
- 21.Servières, M.; Renaudin, V.; Dupuis, A.; et al. Visual and visual-inertial SLAM: State of the art, classification, and experimental benchmarking. J. Sens., 2021, 2021: 2054828. doi: 10.1155/2021/2054828
- 22.Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell., 2018, 40: 611−625. doi: 10.1109/TPAMI.2017.2658577
- 23.Lin, Z.L.; Zhang, G.L.; Yao, E.L.; et al. Stereo visual odometry based on motion object detection in the dynamic scene. Acta Opt. Sin., 2017, 37: 1115001. doi: 10.3788/AOS201737.1115001
- 24.Qin, T.; Shen, S.J. Online temporal calibration for monocular visual-inertial systems. In
Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018 ; IEEE: New York, 2018; pp. 3662–3669. doi:10.1109/IROS.2018.8593603 - 25.Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Rob., 2017, 33: 1255−1262. doi: 10.1109/TRO.2017.2705103
- 26.Kümmerle, R.; Grisetti, G.; Strasdat, H.;
et al . g2o: A general framework for graph optimization. InProceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011 ; IEEE: New York, 2011; pp. 3607–3613. doi:10.1109/ICRA.2011.5979949 - 27.Qin, T.; Li, P.L.; Shen, S. J. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Rob., 2018, 34: 1004−1020. doi: 10.1109/TRO.2018.2853729

How to Cite
Ma, C.; Cheng, P.; Cai, C. Localization and Mapping Method Based on Multimodal Information Fusion and Deep Learning for Dynamic Object Removal. International Journal of Network Dynamics and Intelligence 2024, 3 (2), 100008. https://doi.org/10.53941/ijndi.2024.100008.
RIS
BibTex
Copyright & License

Copyright (c) 2024 by the authors.
This work is licensed under a Creative Commons Attribution 4.0 International License.
Contents
References
 Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia
Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia General Inquiries: info@sciltp.com
General Inquiries: info@sciltp.com