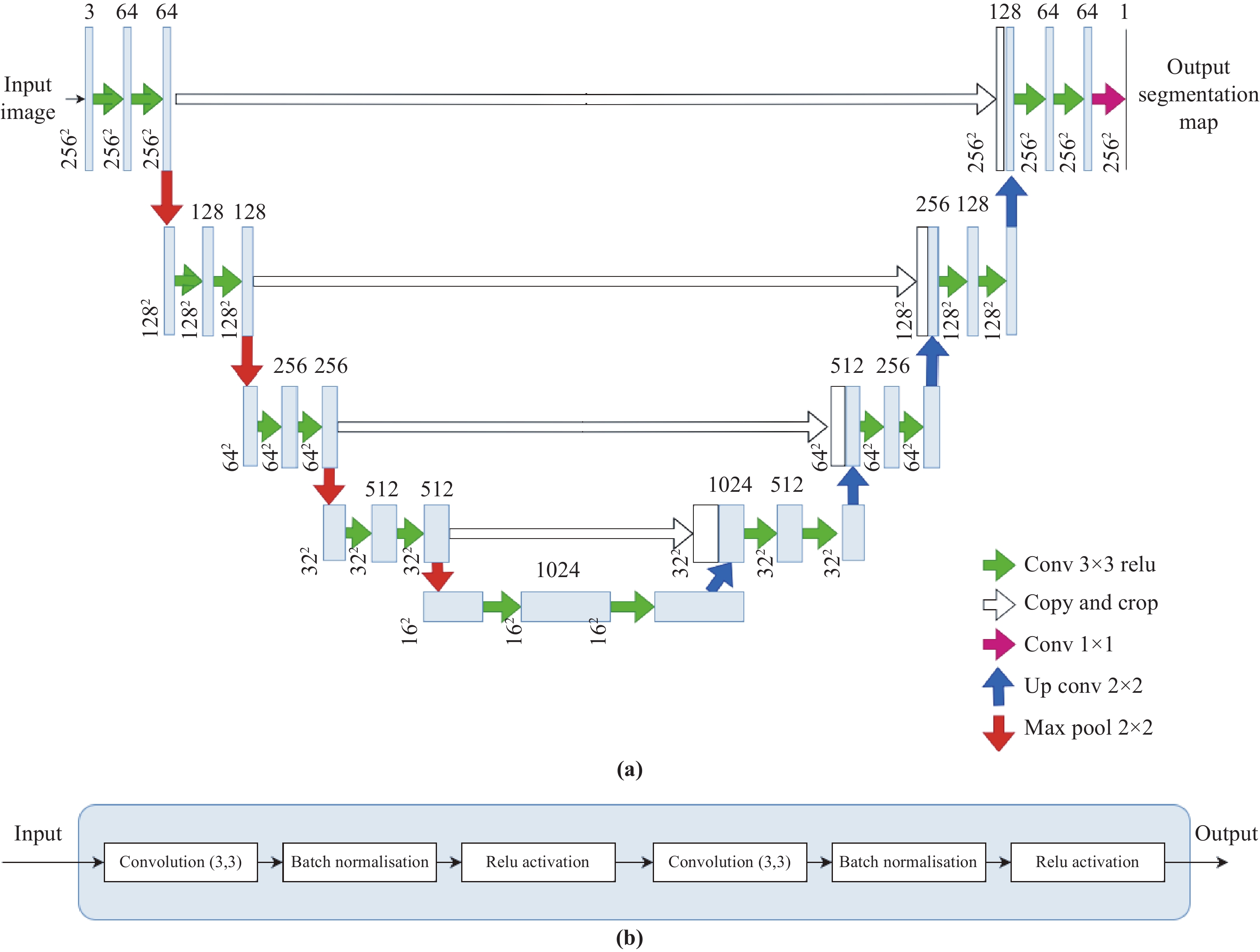
Medical imaging plays a crucial role in modern healthcare by providing non-invasive visualisation of internal structures and abnormalities, enabling early disease detection, accurate diagnosis, and treatment planning. This study aims to explore the application of deep learning models, particularly focusing on the UNet architecture and its variants, in medical image segmentation. We seek to evaluate the performance of these models across various challenging medical image segmentation tasks, addressing issues such as image normalization, resizing, architecture choices, loss function design, and hyperparameter tuning. The findings reveal that the standard UNet, when extended with a deep network layer, is a proficient medical image segmentation model, while the Res-UNet and Attention Res-UNet architectures demonstrate smoother convergence and superior performance, particularly when handling fine image details. The study also addresses the challenge of high class imbalance through careful preprocessing and loss function definitions. We anticipate that the results of this study will provide useful insights for researchers seeking to apply these models to new medical imaging problems and offer guidance and best practices for their implementation.
- Open Access
- Article
UNet and Variants for Medical Image Segmentation
- Walid Ehab,
- Lina Huang,
- Yongmin Li *
Author Information
Received: 22 Sep 2023 | Accepted: 25 Dec 2023 | Published: 26 Jun 2024
Abstract
Graphical Abstract
Keywords
medical imaging | segmentation | performance analysis | UNet | Res-UNet | Attention Res-UNet
References
- 1.Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In
18th International Conference on Medical Image Computing and Computer-Assisted Intervention ,Munich ,Germany ,5 –9 October 2015 ; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. doi: 10.1007/978-3-319-24574-4_28 - 2.He, K.M.; Zhang, X.Y.; Ren, S.Q.;
et al . Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR ),Las Vegas ,NV ,USA ,27 –30 June 2016 ; IEEE: New York, 2016; pp. 770–778. doi: 10.1109/CVPR.2016.90 - 3.Maji, D.; Sigedar, P.; Singh, M. Attention Res-UNet with Guided Decoder for semantic segmentation of brain tumors. Biomed. Signal Process. Control, 2022, 71: 103077. doi: 10.1016/j.bspc.2021.103077
- 4.Liu, L.L.; Cheng, J.H.; Quan, Q.; et al. A survey on U-shaped networks in medical image segmentations. Neurocomputing, 2020, 409: 244−258. doi: 10.1016/j.neucom.2020.05.070
- 5.Haque, I.R.I.; Neubert, J. Deep learning approaches to biomedical image segmentation. Inform. Med. Unlocked, 2020, 18: 100297. doi: 10.1016/j.imu.2020.100297
- 6.Lock, F.K.; Carrieri, D. Factors affecting the UK junior doctor workforce retention crisis: An integrative review. BMJ Open, 2022, 12: e059397. doi: 10.1136/bmjopen-2021-059397
- 7.Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; et al. Active shape models-their training and application. Comput. Vis. Image Underst., 1995, 61: 38−59. doi: 10.1006/cviu.1995.1004
- 8.Litjens, G.; Kooi, T.; Bejnordi, B.E.; et al. A survey on deep learning in medical image analysis. Med. Image Anal., 2017, 42: 60−88. doi: 10.1016/j.media.2017.07.005
- 9.Fraz, M.M.; Remagnino, P.; Hoppe, A.; et al. Blood vessel segmentation methodologies in retinal images–a survey. Comput. Methods Programs Biomed., 2012, 108: 407−433. doi: 10.1016/j.cmpb.2012.03.009
- 10.Ren, S.Q.; He, K.M.; Girshick, R.;
et al . Faster R-CNN: Towards real-time object detection with region proposal networks. InProceedings of the 28th International Conference on Neural Information Processing Systems ,Montreal ,Canada ,7 –12 December 2015 ; MIT Press: Cambridge, 2015; pp. 91–99. - 11.Valvano, G.; Santini, G.; Martini, N.; et al. Convolutional neural networks for the segmentation of microcalcification in mammography imaging. J. Healthc. Eng., 2019, 2019: 9360941. doi: 10.1155/2019/9360941
- 12.Callaghan, M.F.; Josephs, O.; Herbst, M.; et al. An evaluation of prospective motion correction (PMC) for high resolution quantitative MRI. Front. Neurosci., 2015, 9: 97. doi: 10.3389/fnins.2015.00097
- 13.Iglesias, J.E.; Liu, C.Y.; Thompson, P.M.; et al. Robust brain extraction across datasets and comparison with publicly available methods. IEEE Trans. Med. Imaging, 2011, 30: 1617−1634. doi: 10.1109/TMI.2011.2138152
- 14.Havaei, M.; Davy, A.; Warde-Farley, D.; et al. Brain tumor segmentation with Deep Neural Networks. Med. Image Anal., 2017, 35: 18−31. doi: 10.1016/j.media.2016.05.004
- 15.Fritscher, K.D.; Peroni, M.; Zaffino, P.; et al. Automatic segmentation of head and neck CT images for radiotherapy treatment planning using multiple atlases, statistical appearance models, and geodesic active contours. Med. Phys., 2014, 41: 051910. doi: 10.1118/1.4871623
- 16.Ma, J.L.; Wu, F.; Jiang, T.A.; et al. Cascade convolutional neural networks for automatic detection of thyroid nodules in ultrasound images. Med. Phys., 2017, 44: 1678−1691. doi: 10.1002/mp.12134
- 17.Huda, W.; Slone, R.M.
Review of Radiologic Physics , 2nd ed.; Lippincott Williams & Wilkins: Philadelphia, 2003. - 18.Zaitsev, M.; Maclaren, J.; Herbst, M. Motion artifacts in MRI: A complex problem with many partial solutions. J. Magn. Reson. Imaging, 2015, 42: 887−901. doi: 10.1002/jmri.24850
- 19.Plenge, E.; Poot, D.H.J.; Bernsen, M.; et al. Super-resolution methods in MRI: Can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time?. Magn. Reson. Med., 2012, 68: 1983−1993. doi: 10.1002/mrm.24187
- 20.Rabbani, H.; Vafadust, M.; Abolmaesumi, P.; et al. Speckle noise reduction of medical ultrasound images in complex wavelet domain using mixture priors. IEEE Trans. Biomed. Eng., 2008, 55: 2152−2160. doi: 10.1109/TBME.2008.923140
- 21.Wells, P.N.T.; Liang, H.D. Medical ultrasound: Imaging of soft tissue strain and elasticity. J. Roy. Soc. Interface, 2011, 8: 1521−1549. doi: 10.1098/rsif.2011.0054
- 22.Duarte-Salazar, C.A.; Castro-Ospina, A.E.; Becerra, M.A.; et al. Speckle noise reduction in ultrasound images for improving the metrological evaluation of biomedical applications: An overview. IEEE Access, 2020, 8: 15983−15999. doi: 10.1109/ACCESS.2020.2967178
- 23.Kamiyoshihara, M.; Otaki, A.; Nameki, T.; et al. Congenital bronchial atresia treated with video-assisted thoracoscopic surgery; report of a case. Kyobu Geka, 2004, 57: 591−593
- 24.Aichinger, H.; Dierker, J.; Joite-Barfuß, S.;
et al .Radiation Exposure and Image Quality in X-Ray Diagnostic Radiology :Physical Principles and Clinical Applications , 2nd ed.; Springer: Berlin, Heidelberg, 2012. doi: 10.1007/978-3-642-11241-6 - 25.Chen, J.Y.; Zheng, H.B.; Lin, X.; et al. A novel image segmentation method based on fast density clustering algorithm. Eng. Appl. Artif. Intell., 2018, 73: 92−110. doi: 10.1016/j.engappai.2018.04.023
- 26.Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging, 2004, 13: 146−165. doi: 10.1117/1.1631315
- 27.Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis., 2004, 59: 167−181. doi: 10.1023/B:VISI.0000022288.19776.77
- 28.Beucher, S. The watershed transformation applied to image segmentation. Scann. Microsc., 1992, 1992: 28
- 29.Jain, A.K.; Dubes, R.C.
Algorithms for Clustering Data ; Prentice-Hall, Inc.: Englewood Cliffs, 1988. - 30.Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis., 1988, 1: 321−331. doi: 10.1007/BF00133570
- 31.Kaba, D.; Salazar-Gonzalez, A.G.; Li, Y.M.;
et al . Segmentation of retinal blood vessels using Gaussian mixture models and expectation maximisation. In2nd International Conference on Health Information Science ,London ,UK ,25 –27 March 2013 ; Springer: Berlin/Heidelberg, Germany, 2013; pp. 105–112. doi: 10.1007/978-3-642-37899-7_9 - 32.Kaba, D.; Wang, C.; Li, Y.M.; et al. Retinal blood vessels extraction using probabilistic modelling. Health Inf. Sci. Syst., 2014, 2: 2. doi: 10.1186/2047-2501-2-2
- 33.Kaba, D.; Wang, Y.X.; Wang, C.; et al. Retina layer segmentation using kernel graph cuts and continuous max-flow. Opt. Express, 2015, 23: 7366−7384. doi: 10.1364/OE.23.007366
- 34.Dodo, B.I.; Li, Y.M.; Eltayef, K.;
et al . Graph-cut segmentation of retinal layers from OCT images. In11th International Joint Conference on Biomedical Engineering Systems and Technologies ,Funchal ,Madeira ,Portugal ,19 –21 January 2018 ; SciTePress: Setúbal, Portugal, 2018; pp. 35–42. doi: 10.5220/0006580600350042 - 35.Salazar-Gonzalez, A.; Kaba, D.; Li, Y.M.; et al. Segmentation of the blood vessels and optic disk in retinal images. IEEE J. Biomed. Health Inform., 2014, 18: 1874−1886. doi: 10.1109/JBHI.2014.2302749
- 36.Salazar-Gonzalez, A.; Li, Y.M.; Kaba, D. MRF reconstruction of retinal images for the optic disc segmentation. In
1st International Conference on Health Information Science ,Beijing ,China ,8 –10 April 2012 ; Springer: Berlin/Heidelberg, Germany, 2012; pp. 88–99. doi: 10.1007/978-3-642-29361-0_13 - 37.Salazar-Gonzalez, A.G.; Li, Y.M.; Liu, X.H. Optic disc segmentation by incorporating blood vessel compensation. In
IEEE Third International Workshop on Computational Intelligence in Medical Imaging ,Paris ,France ,11 –15 April 2011 ; IEEE: New York, 2011; pp. 1–8. doi: 10.1109/CIMI.2011.5952040 - 38.Dodo, B.I.; Li, Y.M.; Eltayef, K.; et al. Automatic annotation of retinal layers in optical coherence tomography images. J. Med. Syst., 2019, 43: 336. doi: 10.1007/s10916-019-1452-9
- 39.Dodo, B.I.; Li, Y.M.; Kaba, D.; et al. Retinal layer segmentation in optical coherence tomography images. IEEE Access, 2019, 7: 152388−152398. doi: 10.1109/ACCESS.2019.2947761 doi: 10.1109/ACCESS.2019.2947761
- 40.Wang, C.; Kaba, D.; Li, Y.M. Level set segmentation of optic discs from retinal images. J. Med. Bioeng., 2015, 4: 213−220. doi: 10.12720/jomb.4.3.213-220
- 41.Wang, C.; Wang, Y.X.; Li, Y.M. Automatic choroidal layer segmentation using Markov random field and level set method. IEEE J. Biomed. Health Inform., 2017, 21: 1694−1702. doi: 10.1109/JBHI.2017.2675382
- 42.Drozdzal, M.; Chartrand, G.; Vorontsov, E.; et al. Learning normalized inputs for iterative estimation in medical image segmentation. Med. Image Anal., 2018, 44: 1−13. doi: 10.1016/j.media.2017.11.005
- 43.Li, H.; Zeng, N.Y.; Wu, P.S.; et al. Cov-Net: A computer-aided diagnosis method for recognizing COVID-19 from chest X-ray images via machine vision. Expert Syst. Appl., 2022, 207: 118029. doi: 10.1016/j.eswa.2022.118029
- 44.Zeng, N.Y.; Li, H.; Peng, Y.H. A new deep belief network-based multi-task learning for diagnosis of Alzheimer’s disease. Neural Comput. Appl., 2023, 35: 11599−11610. doi: 10.1007/s00521-021-06149-6
- 45.Li, H.; Wu, P.S.; Zeng, N.Y.; et al. A survey on parameter identification, state estimation and data analytics for lateral flow immunoassay: From systems science perspective. Int. J. Syst. Sci., 2022, 53: 3556−3576. doi: 10.1080/00207721.2022.2083262
- 46.Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell., 2017, 39: 2481−2495. doi: 10.1109/TPAMI.2016.2644615
- 47.Kao, P.Y.; Ngo, T.; Zhang, A.;
et al . Brain tumor segmentation and tractographic feature extraction from structural MR images for overall survival prediction. In4th International Workshop on Brainlesion :Glioma ,Multiple Sclerosis ,Stroke and Traumatic Brain Injuries ,Granada ,Spain ,16 September 2018 ; Springer: Berlin/Heidelberg, Germany, 2019; pp. 128–141. doi: 10.1007/978-3-030-11726-9_12 - 48.Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; et al. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods, 2021, 18: 203−211. doi: 10.1038/s41592-020-01008-z
- 49.McConnell, N.; Miron, A.; Wang, Z.D.;
et al . Integrating residual, dense, and inception blocks into the nnUNet. InIEEE 35th International Symposium on Computer Based Medical Systems ,Shenzen ,China ,21 –23 July 2022 ; IEEE: New York, 2022; pp. 217–222. doi: 10.1109/CBMS55023.2022.00045 - 50.Ndipenoch, N.; Miron, A.; Wang, Z.D.;
et al . Simultaneous segmentation of layers and fluids in retinal OCT images. In15th International Congress on Image and Signal Processing ,BioMedical Engineering and Informatics ,Beijing ,China ,5 –7 November 2022 ; IEEE: New York, 2022; pp. 1–6. doi: 10.1109/CISP-BMEI56279.2022.9979957 - 51.Ndipenoch, N.; Miron, A.D.; Wang, Z.D.;
et al . Retinal image segmentation with small datasets. In16th International Joint Conference on Biomedical Engineering Systems and Technologies ,Lisbon ,Portugal ,16 –18 February 2023 ; SciTePress: Setúbal, Portugal, 2023; pp. 129–137. doi: 10.5220/0011779200003414 - 52.Buda, M. Brain MRI segmentation.
- 53.Pedano, N.; Flanders, A.E.; Scarpace, L.;
et al . The cancer genome atlas low grade glioma collection (TCGA-LGG) (version 3). The Cancer Imaging Archive, 2016. - 54.Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; et al. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph., 2015, 42: 99−111. doi: 10.1016/j.compmedimag.2015.02.007
- 55.Bernard, O.; Lalande, A.; Zotti, C.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved?. IEEE Trans. Med. Imaging, 2018, 37: 2514−2525. doi: 10.1109/TMI.2018.2837502
- 56.Ma, G.J.; Wang, Z.D.; Liu, W.B.; et al. A two-stage integrated method for early prediction of remaining useful life of lithium-ion batteries. Knowl.-Based Syst., 2023, 259: 110012. doi: 10.1016/j.knosys.2022.110012
- 57.Ma, G.J.; Wang, Z.D.; Liu, W.B.; et al. Estimating the state of health for lithium-ion batteries: A particle swarm optimization-assisted deep domain adaptation approach. IEEE/CAA J. Autom. Sin., 2023, 10: 1530−1543. doi: 10.1109/JAS.2023.123531

How to Cite
Ehab, W.; Huang, L.; Li, Y. UNet and Variants for Medical Image Segmentation. International Journal of Network Dynamics and Intelligence 2024, 3 (2), 100009. https://doi.org/10.53941/ijndi.2024.100009.
RIS
BibTex
Copyright & License

Copyright (c) 2024 by the authors.
This work is licensed under a Creative Commons Attribution 4.0 International License.
Contents
References
 Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia
Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia General Inquiries: info@sciltp.com
General Inquiries: info@sciltp.com