
Downloads
 Download
Download






This work is licensed under a Creative Commons Attribution 4.0 International License.
Article
Adaptive Neural Event-Triggered Output-Feedback Optimal Tracking Control for Discrete-Time Pure-Feedback Nonlinear Systems
Wei Wang 1, and Min Wang 1,2,*
1 School of Automation Science and Engineering, South China University of Technology, Guangzhou 510641, China
2 Pengcheng Laboratory, Shenzhen 518055, China
* Correspondence: auwangmin@scut.edu.cn
Received: 20 December 2023
Accepted: 30 January 2024
Published: 26 June 2024
Abstract: In this article, a novel event-triggered (ET) output-feedback optimal tracking control scheme is developed for a class of uncertain discrete-time nonlinear systems in the pure-feedback form with immeasurable states. Firstly, different from the traditional n-step-ahead input-output prediction model, the immeasurable states of the system are estimated in real time by designing a neural network (NN) state observer. Then, the implicit function theorem and the mean value theorem are combined to tackle the nonaffine terms. The variable substitution approach is applied to overcome the causal contradiction problem during the backstepping design, and meanwhile the n-step time delays caused by the traditional n-step-ahead prediction model are avoided. Subsequently, the critic NN and the action NN are employed to minimize the system long-term performance measure. Under the adaptive critic design framework, an optimal controller is designed to obtain the optimal control performance. Furthermore, an ET mechanism is embedded between sensors and controllers to reduce network burden. A novel ET condition is developed to save network resources and guarantee the desired tracking control performance. According to the Lyapunov stability analysis, all the closed-loop system signals are guaranteed to be uniformly ultimately bounded.
Keywords:
adaptive neural control optimal control event-triggered control neural state observer pure-feedback systems1. Introduction
Over the past few decades, the control design problem for a class of uncertain lower triangular nonlinear systems has attracted extensive attention. In reality, abundant actual plants can be constructed as lower triangular nonlinear systems, such as mechanical systems [1], marine surface vessels [2], unmanned aerial vehicles [3] and robotic manipulators [4]. To handle the uncertain nonlinear functions presented in dynamical systems, adaptive neural networks (NNs) or/and fuzzy-logic systems have been widely employed in engineering practice owning to their universal approximation abilities [5, 6]. Based on the function approximator and backstepping technique, plenty of effective control schemes have been developed for uncertain nonlinear systems in various fields, such as state constraints [7], input constraints [8], actuator faults [9], and predefined performance [10]. These works are mostly based on the continuous-time (CT) strict-feedback nonlinear systems, while the control design problem of pure-feedback nonlinear systems is more complicated due to the existence of unknown nonaffine functions [11]. With the development of computer technology and digital control, the studies of discrete-time nonlinear systems have become a hot topic [12]. Compared with CT affine nonlinear systems, the control design for discrete-time pure-feedback nonlinear (DTPFN) systems is usually more challenging, and there exist rarely research works for DTPFN systems.
For discrete-time nonlinear systems, the causal contradiction problem is difficult to overcome during the controller design procedure via the backstepping technique [13]. The designed controller typically requires the future system signals which are unavailable in practice. In [14], the causal contradiction problem was effectively overcomed by transforming the original system into the n-step-ahead prediction model. In [15], based on the implicit function theorem and the mean value theorem, a DTPFN system was transformed into the n-step-ahead input-output prediction model to tackle the causal contradiction problem and immeasurable system states. According to the n-step-ahead prediction model, a lot of important works have been developed for discrete-time nonlinear systems [16−18]. However, there are still two limitations in these works: the process noise and measurable noise are not considered in the closed-loop system, and the n-step time delays exist in the transformed system. To overcome these two limitations, a variable substitution approach was proposed in [19] to solve the causal contradiction problem, which simplifies the controller design and avoids the n-step time delays. So far, the variable substitution approach has been mainly employed to solve the control design problem for discrete-time strict-feedback nonlinear systems. Nevertheless, there are few results for the control design of DTPFN systems based on the variable substitution approach because of the uncertain nonaffine terms. In [20], by combining the implicit function theorem and the mean value theorem, the variable substitution approach was applied to design an ET optimal tracking control scheme for a class of second-order DTPFN systems.
With the development of information science and wireless communication technology, network-based control has been widely applied in solving the remote control problem [21−24]. The system signals are transmitted from sensors to controllers or from controllers to actuators by means of communication network. For increasingly complex control tasks, a large number of system signals are transmitted through communication network, which will increase network burden. Due to limited network resources, some undesirable phenomena may occur, such as transmission delays [25], packet loss [26], disorders [27], and network attacks [28, 29]. To save network resources and reduce network burden, an event-triggered control (ETC) scheme was developed in [30]. Different from the traditional time-triggered control (TTC) technique, system signals are transmitted from sensors to controllers only when the presented event-triggered (ET) condition is satisfied. Based on the ET mechanism, many meaningful works were proposed for CT nonlinear systems [31−33]. In [34], an ET optimal controller was designed for CT nonlinear systems based on reinforcement learning. In [35, 36], the ETC scheme was further extended to multi-agent systems. On the basis of the n-step-ahead prediction model, there exist many valuable ETC research works for discrete-time nonlinear systems [37−39]. However, these works need to calculate n intermediate ET conditions and n virtual control laws. In order to save computation resources and simplify the ET condition, a novel ETC scheme was proposed in [40] for discrete-time nonlinear systems by the variable substitution approach. In practice, the states of some physical systems are immeasurable because of sensor limitations [41−43]. Based on the neural state observer and the variable substitution approach, an ET adaptive neural control scheme has been proposed in [44, 45] for discrete-time strict-feedback systems with known constant gains. Until now, the neural state observer of DTPFN systems has never been considered in existing literature because of coupling.
In modern industry, optimal control can obtain better control performance and make the cost of the controller smaller. Dynamic programming is an effective technique to solve optimization problems, but it may cause ``curse of dimensionality" for high-order systems [46]. In order to solve the difficulty, an adaptive critic design (ACD) scheme was proposed in [47] to design the optimal controller based on the critic-action NN structure, where the system long-term performance measure was considered to obtain the optimal control performance. There exist a lot of optimal control works for nonlinear systems which are required to satisfy the matching condition [48−50]. Based on the ACD framework and backstepping technique, many important works have been reported for nonlinear systems with the mismatching condition in different phenomena, such as state constraints [51], dead-zone [52], actuator faults [53], and unknown backlashlike hysteresis [54]. However, the existing optimal research works are mostly based on state feedback and TTC. It is challenging to develop the ET output-feedback optimal tracking control scheme for DTPFN systems with immeasurable states and limited network resources.
According to the above discussions, the design problem of ET output-feedback optimal tracking control is addressed in this paper for a class of uncertain DTPFN systems. Firstly, an NN-based state observer is constructed to estimate the immeasurable system states. Then, the variable substitution approach is applied to overcome the causal contradiction problem during backstepping procedure, which avoids the n-step time delays. The implicit function theorem and mean value theorem are combined to tackle the nonaffine terms. In order to obtain the optimal control performance, an ACD framework is constructed to design the optimal tracking controller. A critic-action NN structure is constructed to minimize the long-term performance measure. Moreover, an ET mechanism is embedded between sensors and controllers. A novel ET condition is presented to save network resources and guarantee the stability of the closed-loop system. The proposed optimal control scheme guarantees the optimal tracking control performance, estimates the immeasurable system states, and reduces network burden. To be more specific, the main contributions of this paper are highlighted as follows.
1) A neural state observer is constructed to estimate the immeasurable system states, which decouples the designed observer and controller. Based on the observer states and ET mechanism, the actual controller is designed to guarantee the tracking control performance. According to state estimation errors and tracking errors, a novel ET condition is designed to save network resources, which improves transient control performance and reduces unnecessary triggered events in steady-state process.
2) By combining the implicit function theorem and mean value theorem, the variable substitution approach is employed to overcome the causal contradiction problem for uncertain DTPFN systems during the backstepping design procedure. The proposed scheme avoids the n-step time delays caused by the traditional n-step-ahead prediction model.
3) The ACD framework is developed to design an optimal controller, which guarantees the optimal tracking control performance. To obtain the action NN weight updating laws, the variable substitution approach is applied to transform the unknown term into the available signal iteratively, which is effective to implement the optimal controller.
2. Problem Formulation and Preliminaries
In this paper, the optimal tracking control problem of an uncertain DTPFN system with immeasurable states is considered as follows:
where for are system state vectors, and are ststem control input and output, respectively. are unknown nonlinear functions for . is the bounded external disturbance and satisfies with being a positive constant. Only the system output can be obtained and the system states are assumed to be immeasurable.
The system uncertain nonlinear functions , , and are continuous with respect to all the arguments and continuously differentiable with respect to the second argument.
For the convenience of theoretical analysis, define the following nonlinear functions:
There exist two positive constants such that , .
Without loss of generality, it is supposed that the signs of are all positive. To simplify the notation, define and .
The system function is a Lipschitz function with respect to . There exists a positive constant such that
Remark 1: Adaptive nerual output-feedback control scheme was proposed in [15, 18] for uncertain DTPFN systems by transforming the original system into the n-step-ahead input-output prediction model. The transformed system containes the current and past disturbances. Moreover, the original system functions are required to satisfy the Lipschitz condition. In this paper, by employing the variable substitution approach, it is unnecessary to assume that all the system functions satisfy the Lipschitz condition, which relaxes the restrictions of the closed-loop system. Additionally, the controller is directly designed in the original system without system transformation. Thus, the past disturbances will not appear in the system function.
2.1. High-Order Neural Network
In this paper, a high-order neural network (HONN) is applied to approximate the uncertain nonlinear function on a compact set as follows:
where is the input vector, is the ideal constant weight vector, is the number of neurons, is the approximation error, and is the basis function vector. In the HONN, , , , where is a collection of not-ordered subsets of , , and is a non-negative integer. According to the universal approximation property of the HONN, if is selected to be sufficiently large, the approximation error satisfies , where is an arbitrarily small positive constant.
The basis function vector satisfies the local Lipschitz condition. There exists a positive constant such that .
2.2. Event-Triggered Mechanism
Since the system states are assumed to be immeasurable, an NN-based state observer is employed to estimate the immeasurable states. As displayed in Figure 1, the estimated states are transmitted from the observer to controller through communication network. In order to reduce network burden and save network resources, an ET mechanism is employed and the ET condition is duly designed.
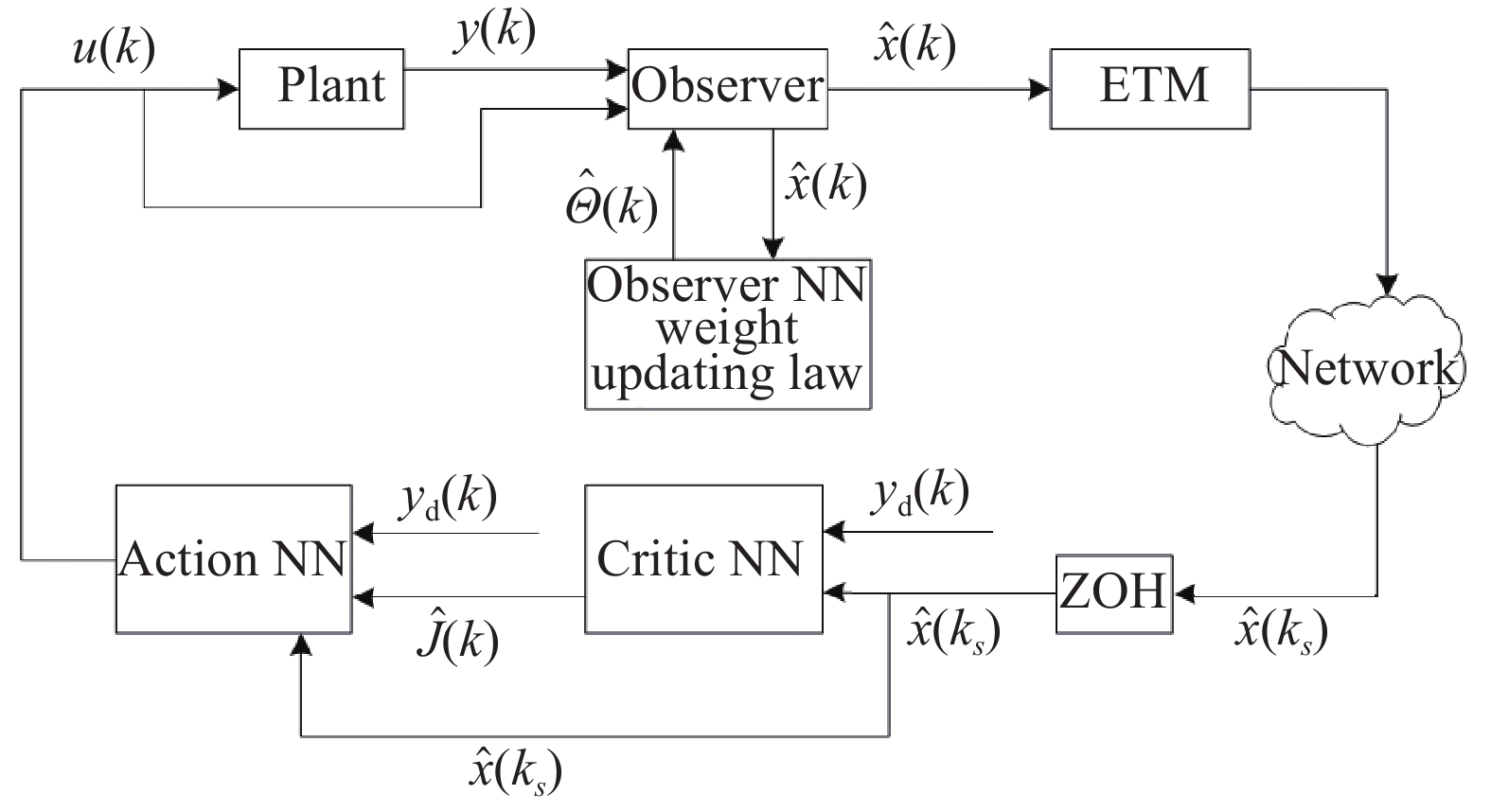
Figure 1. The event-triggered block diagram of the closed-loop system.
The triggering instants are defined by . Let denote the sequence of triggering instants, which is a subsequence of the time sequence . The observer states are transmitted to the controller only when the ET condition is satisfied. To guarantee the tracking control performance of the uncertain closed-loop system, a Zero-Order Holder (ZOH) is employed to keep the last transmitted signals during the triggering interval . The transmitted signals is used to calculate the optimal controller .
To design the ET condition, define the ET error based on the current estimated states and the last transmitted states as follows:
where , for .
3. NN-Based State Observer Design
In this section, an NN-based state observer is designed to estimate the immeasurable system states . To design the state observer, define the following functions:
where is the designed constant, . According to Assumption 3, is bounded and satisfies . Then, the DTPFN system (1) is transformed into the following form:
The HONNs with neurons are employed to approximate the unknown nonlinear functions as follows:
where is the ideal weight vector and the approximation error satisfies , .
To estimate the immeasurable system states, an NN-based state observer is designed as follows:
where is the estimate of , , is the estimate of , is design parameters. Let the state observer weight estimation error .
Define the state estimation error
where , . By combining system (8) with state observer (10), it has
where , and
The designed parameters and are selected such that the matrix is Schur stability. is bounded and satisfies . The state observer NN weights are updated by
where and are positive constants to be designed, , . According to , we have
Remark 2: Inspired by [19], the weight updating law of the neural state observer is designed as (13). In the paper, the input vector of the basis function vector is different from [19]. The observer NN weight updating law (13) is designed according to the Lyapunov stability analysis. From (13), the state observer NN weights can be guaranteed to be UUB.
To simplify the notation, we define
Proof of Theorem 1. To prove the convergence of the state estimation errors and the weight estimation errors, we consider the following Lyapunov function candidate:
with and .
According to the state estimate error system (12), the difference of is calculated as
where . Substituting (14) into the difference of yields
By combining the following equation
and the following Young’s inequalities
we have
where . Combining (18) with (22), we have
where . From (23), if the condition (16) is satisfied, the state estimate errors and the observer NN weight estimate errors are UUB, i.e., .
Remark 3: An output-feedback tracking controller was proposed in [15] for the DTPFN system by transforming the original system into the n-step-ahead input-output prediction model, where the input and output are applied in controller design. However, the measurement noise and process noise cannot be appropriately handled since the system states cannot be observed in real time. To overcome this difficulty, a neural state observer is constructed in this section to estimate the unknown system states in real time.
4. ET Output-Feedback Optimal Tracking Controller Design
In this section, an ET output-feedback optimal tracking controller is constructed based on the variable substitution approach, the neural state observer (10), and the reinforcement learning strategy.
4.1. ET-based Controller Design
Based on the observer states, define the following coordinate transformations:
where is the reference trajectory, and , , are virtual controllers to be designed later. From (24), one has .
According to the system model (1) and coordinate transformation (24), the difference of is calculated as
Based on Assumption 2 and the implicit function theorem, there exists a virtual controller such that
Consider (24), (25) with (26), one has
Based on the mean value theorem, it follows
where .
Noticing that , the dynamic equation of is calculated as
From (29), the term contains the future system state , which causes the causal contradiction problem. Using the variable substitution approach, can be represented as a function of the current system states
Based on the implicit function theorem, there exists a virtual controller such that
Noticing (29), (30) and (31), we obtain
Based on the mean value theorem, it follows
where .
Due to , its difference is calculated as
Using the variable substitution approach, can be represented by the current system states
Based on the implicit function theorem, there exists a virtual controller such that
Consider (34), (35) with (36), we have
Based on the mean value theorem, it follows
where .
For , its difference is calculated as
By similar analysis, the term can be represented by the current system states
Using the implicit function theorem, there exists an ideal controller such that
Using (39), (40) with (41), one has
By the mean value theorem, it can be obtained that
where . Let .
As the nonlinear function is unknown and the ideal controller cannot be implemented directly to control the closed-loop system, an HONN is employed to approximate as follows:
where is the ideal weight vector, is the approximation error with , and is the HONN input vector.
In order to save communication network resources and reduce the transmission burden, the actual controller is designed as follows:
where is the estimate of the ideal weight , . Substituting (44) and (45) into (43) yields
where is the weight estimation error, is a bounded term and satisfies . Let , .
Remark 4: To overcome the causal contradiction problem during the backstepping design procedure, the n-step-ahead prediction model was proposed in [14, 15] for discrete-time nonlinear systems, in which the n-step time delays exist duly. In [19], the variable substitution approach was developed to design the controller for discrete-time strict-feedback systems, where the n-step time delays were successfully avoided. So far, however, there have been few available results on the control design of DTPFN systems based on the variable substitution approach. In this section, the implicit function theorem and the mean value theorem are employed to handle the nonaffine terms. Different from the n-step-ahead prediction model [14, 15], the variable substitution approach is employed to overcome the causal contradiction problem for DTPFN systems without the system transformation.
4.2. Critic-Action Neural Networks Design
4.2.1. Critic Neural Network Design
The output of the critic neural network represents the long-term performance measure of system (1), which indicates the system tracking control performance. To describe the current system performance index, we define the utility function as follows:
where is a positive parameter to be designed. The long-term performance measure is defined by
where is a discount factor, is a positive integer and represents the horizon. According to (48), can be rewritten as the following form:
Equation (49) is a Bellman equation. The function is unknown and difficult to be directly calculated, it can be approximated by a critic NN as follows:
where is the ideal weight vector, is the input vector, and is the approximation error. Let denotes the estimate of . The actual output of the critic NN is calculated as
From (49), the critic NN error function is defined by
Then, we can define the objective function of the critic NN to be minimized as follows:
Applying the ET mechanism and gradient descent method, the weight updating law for is taken as
with , where is the learning rate of the critic NN, and is the indicator function of the ET mechanism defined by
Combining (52), (53) and (54), we obtain
Let the weight estimate error be . Subtracting on both sides of (56) yields
Let , .
4.2.2. Action Neural Network Design
The output of the action neural network is the actual controller . The action NN is constructed to minimize the estimated system performance index function and obtain the optimal tracking controller. The action NN error function is defined as follows:
with and , where is the desired strategic utility function and the desired value for is . Under Assumption 2, we can obtain .
The objective function of the action NN to be minimized is defined as
Based on the ET mechanism and gradient descent method, one has
where , is the learning rate of the action NN. Combining (58), (58), and (60), we have
Note that the weight updating law (61) cannot be directly implemented because and are unknown. To solve this problem, the variable substitution approach is employed to transform into the available signal. According to the error dynamic equation (43), it is obtained that
From (28), (33) and (38), it is derived that
Combining (62) and (63), the following equation can be obtained iteratively by the variable substitution approach
Hence, it can be obtaind that from (64). The term is unknown and bounded, we employ instead of . The weight updating law of the action NN (61) is further rewritten as
It follows from (65) that
The objective of the action NN is to minimize the estimated long-term performance measure and obtain the optimal controller. From (61), it is impossible to implement the action NN weight updating law because of the unknown nonlinear function . In order to overcome this difficulty, the variable substitution approach is applied to transform into the available signal iteratively based on the error dynamic equations. From (65), the available action NN weight updating law is obtained to implement the optimal controller.
5. Stability Analysis
In order to save network resources and guarantee the tracking control performance of the closed-loop system, the ET mechanism is embedded between the observer and controller. Based on the ET error and the tracking error, a novel ET condition is designed as follows
where are positive parameters to be designed. The parameter can reduce unnecessary triggered events when the tracking error converges to the desired region. The parameter can avoid the possible singularity problem and improve transient control performance.
Theorem 2. Consider the DTPFN system (1), the state observer (10) with the NN weight updating law (13), the critic NN (51) with the weight updating law (56), the action NN (45) with the weight updating law (61) and the event-triggered condition (67). The proposed control scheme guarantees all the closed-loop system signals are UUB if the design parameters satisfy the following condition:
Proof of Theorem 2. Choose the following Lyapunov function candidate:
where , , , and .
Under the designed event-triggered condition (67), the proof is divided into the following two cases.
At the triggering instants, the system data is transmitted from the observer to the controller via communication networks. Thus, one has . Based on the error dynamic equations (28), (33), (38), and (46), the difference of is calculated as
Let . From condition (68), one has . Then, it is clear from (70) that
According to the action NN weight error dynamic (66), we have
It follows from (64) that
Substituting (73) into (72) yields
By the inequality , equation (74) can be rewritten as
Consider the critic NN weight error system (57). The difference of is given by
For , it is clear that
For (68), (71), (75), (76), and (77), the difference of the Lyapunov function (69) is calculated as
where is a bounded term. According to the Lyapunov stability theorem, all the closed-loop system signals are UUB at the triggering instants.
In Case 1, and are UUB, which means and are UUB at the triggering instants. In Case 2, and remain unchanged in the event-triggered intervals. Therefore, and are UUB over the entire time series. Then, we can obtain that and are also UUB. Because during the event-triggered intervals, we have . The difference of the Lyapunov function in Case 2 is given by
Using the event-triggered condition (67), we have
where is bounded. From (80), we can conclude that all system signals of the closed-loop systems are UUB during the event-triggered intervals.
According to the proof of two cases, all the closed-loop system signals are UUB over all sampling instants and the tracking error converges to a small neighborhood around the origin.
6. Simulation
In order to demonstrate the feasibility of the developed ET output-feedback optimal control scheme, the following uncertain DTPFN system is considered.
where , , and are the system state vector, system output, and control input, respectively. The unknown system nonlinear functions are chosen as
The external disturbance is . The desired reference signal is with the sampling period . Considering the nonlinear system (81) and the neural state observer (10), the initial conditions are selected as and . The NN weights are initialized by . By employing the trial-and-error method, the numbers of the observer NN nodes are and , respectively. The numbers of the critic NN nodes and the action NN nodes are and , respectively. The design parameters are selected as , , , , , , , , , , and . The ET threshold parameters are chosen as , , , and .
Using the developed adaptive neural ET output-feedback optimal tracking control method, simulation results are displayed in Figures 2-9. From Figure 2, the system output tracks the desired reference signal and the tracking error converges to a small neighborhood around the origin. Figure 3 indicates the trajectories of the system states and the observer states . From Figure 3, the neural state observer can estimate the immeasurable system states well. Figure 4 represents the triggering intervals between two adjacent triggering instants. Based on the ET mechanism, the number of total triggering instants is 1537, which saves approximately of network resources. Figure 5 displays the actual control input and the estimated system long-term performance measure . From Figure 6, it is obvious that the norms of the state observer weights are bounded. Figure 7 indicates that the weights of the critic NN and the action NN are UUB. According to Figures 2-7, all the closed-loop system signals are guaranteed to be UUB during the entire time instants.
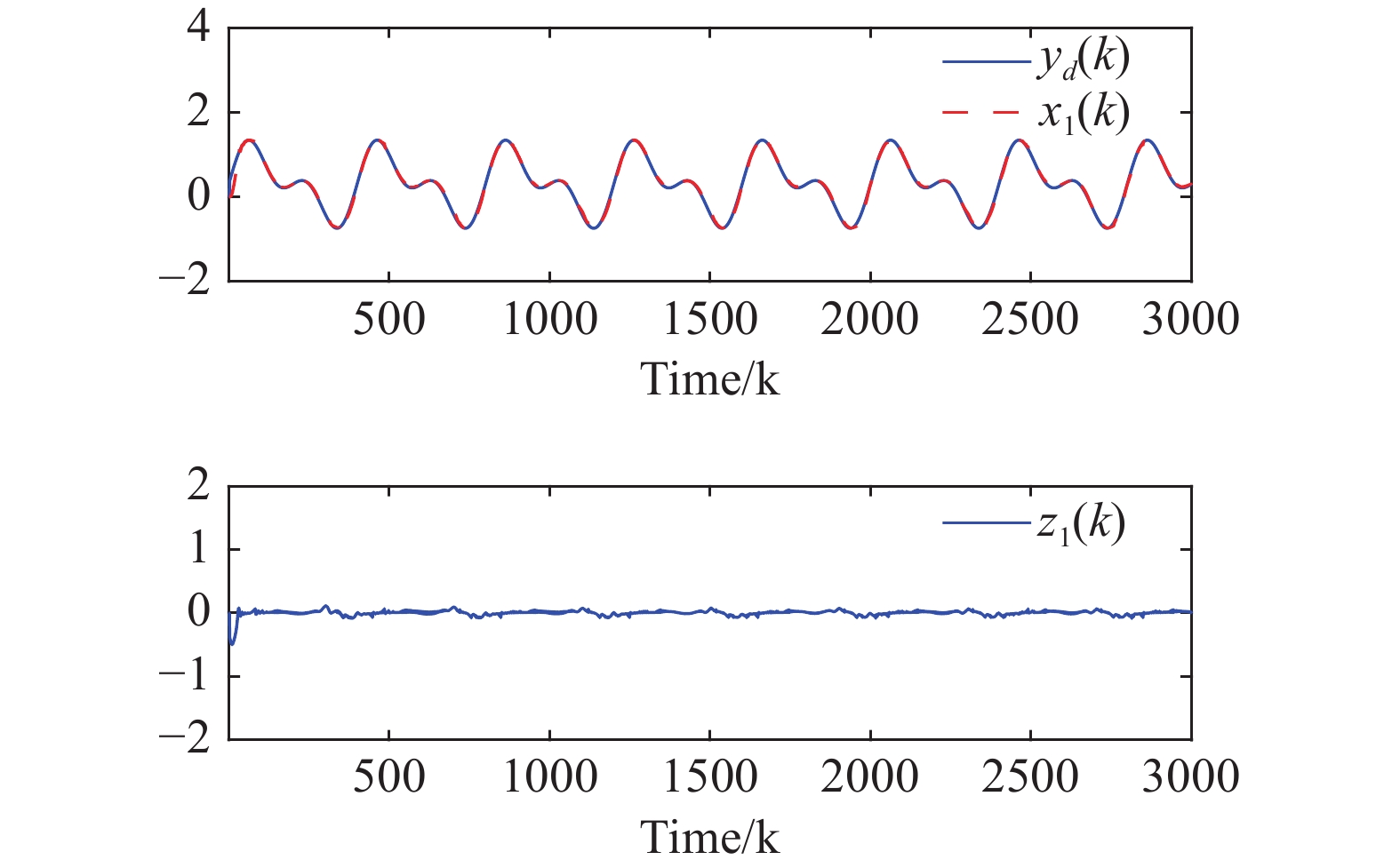
Figure 2. System output , the reference signal , and the tracking error .
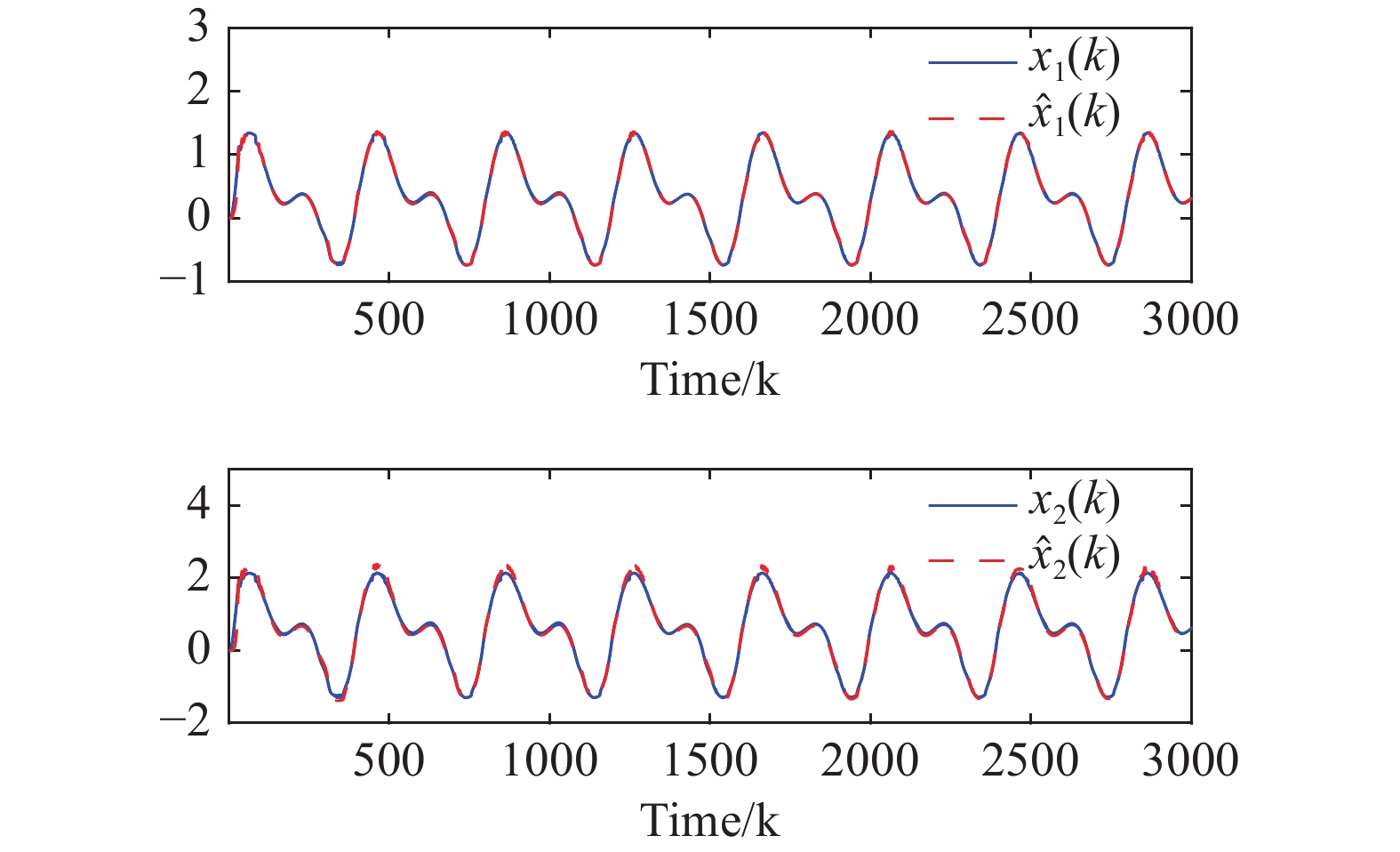
Figure 3. The trajectories of the system states and the observer states .
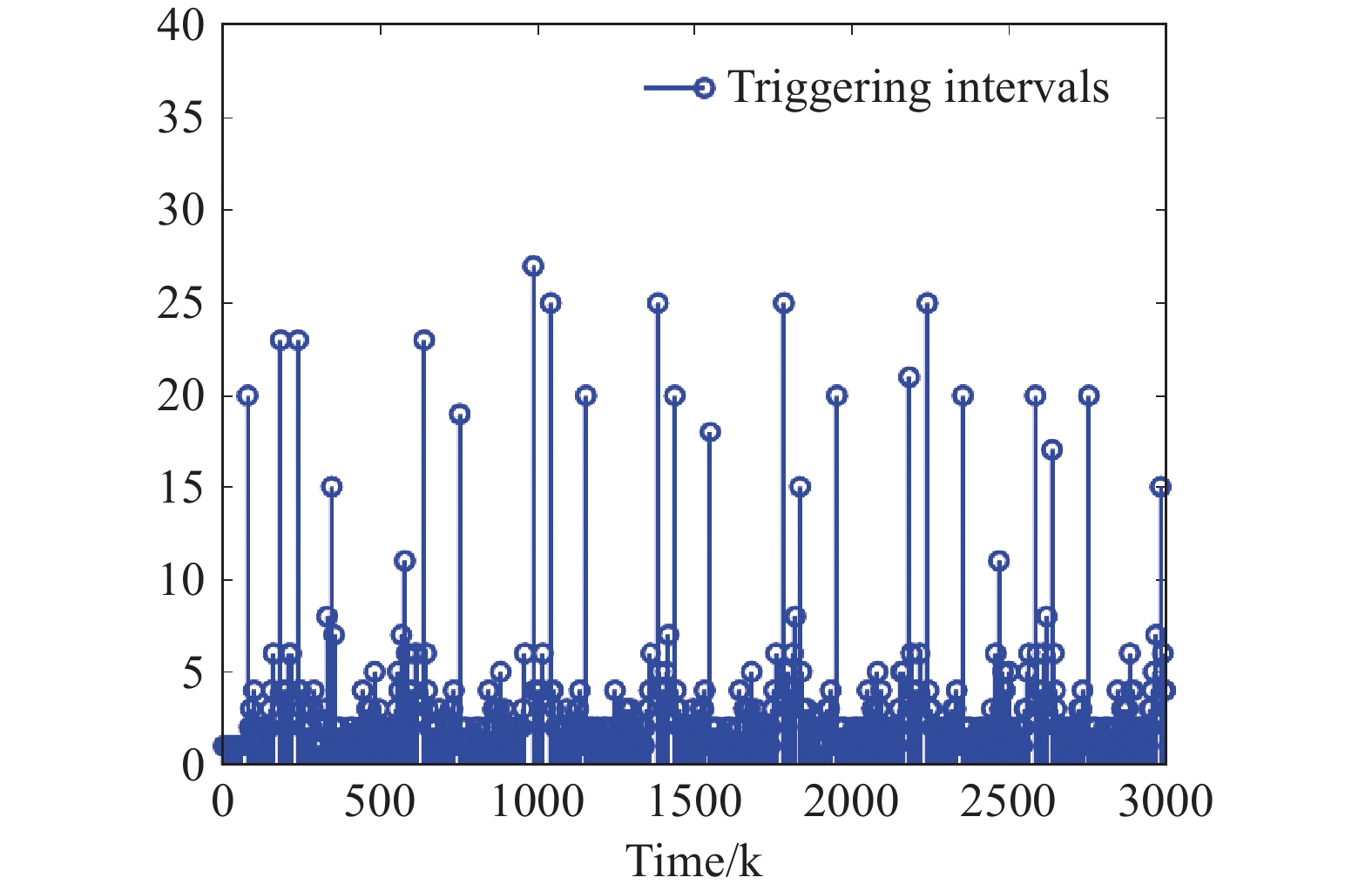
Figure 4. The time intervals between two adjacent triggering instants.
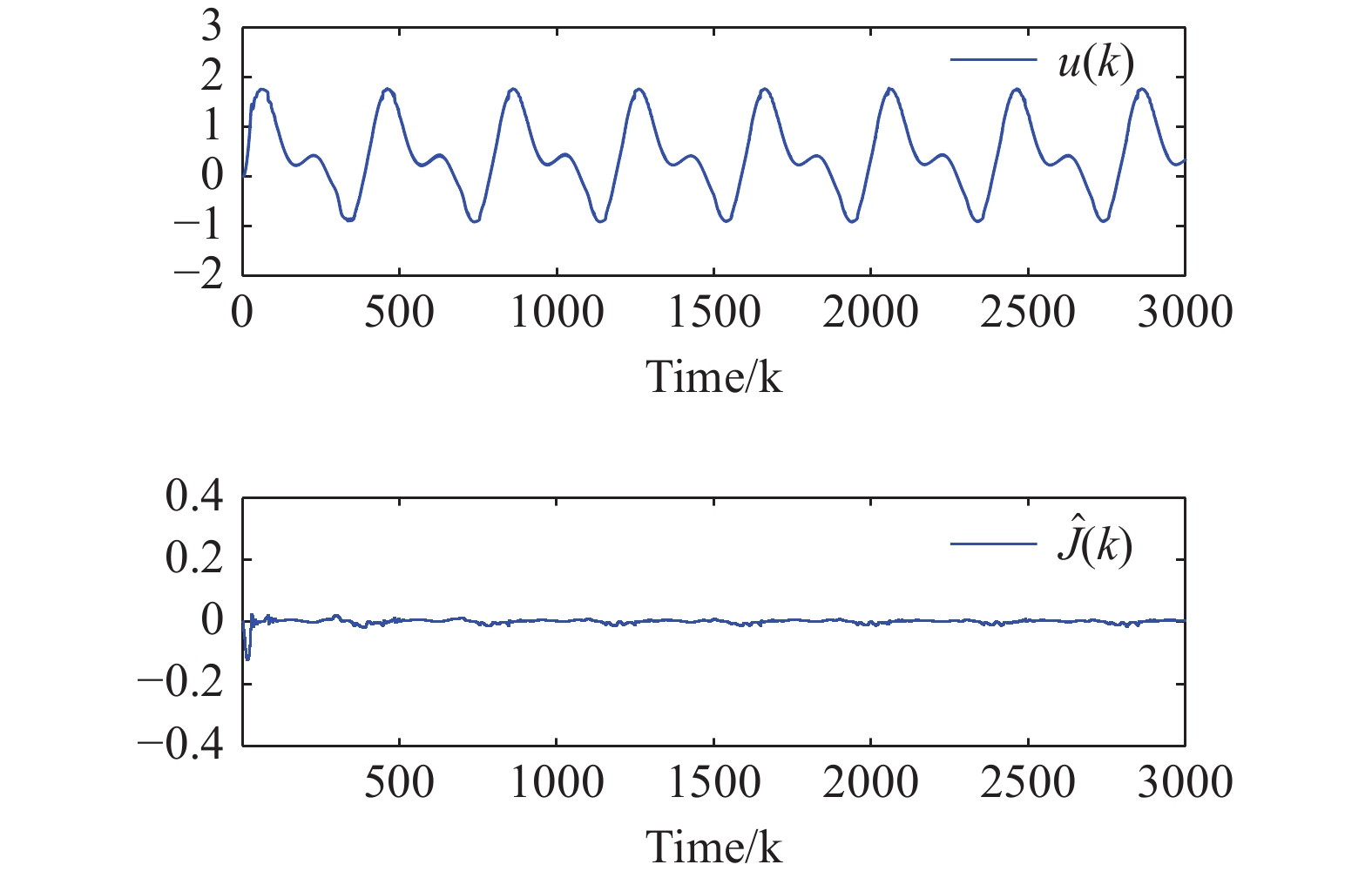
Figure 5. The actual control input and the estimated system long-term performance measure .
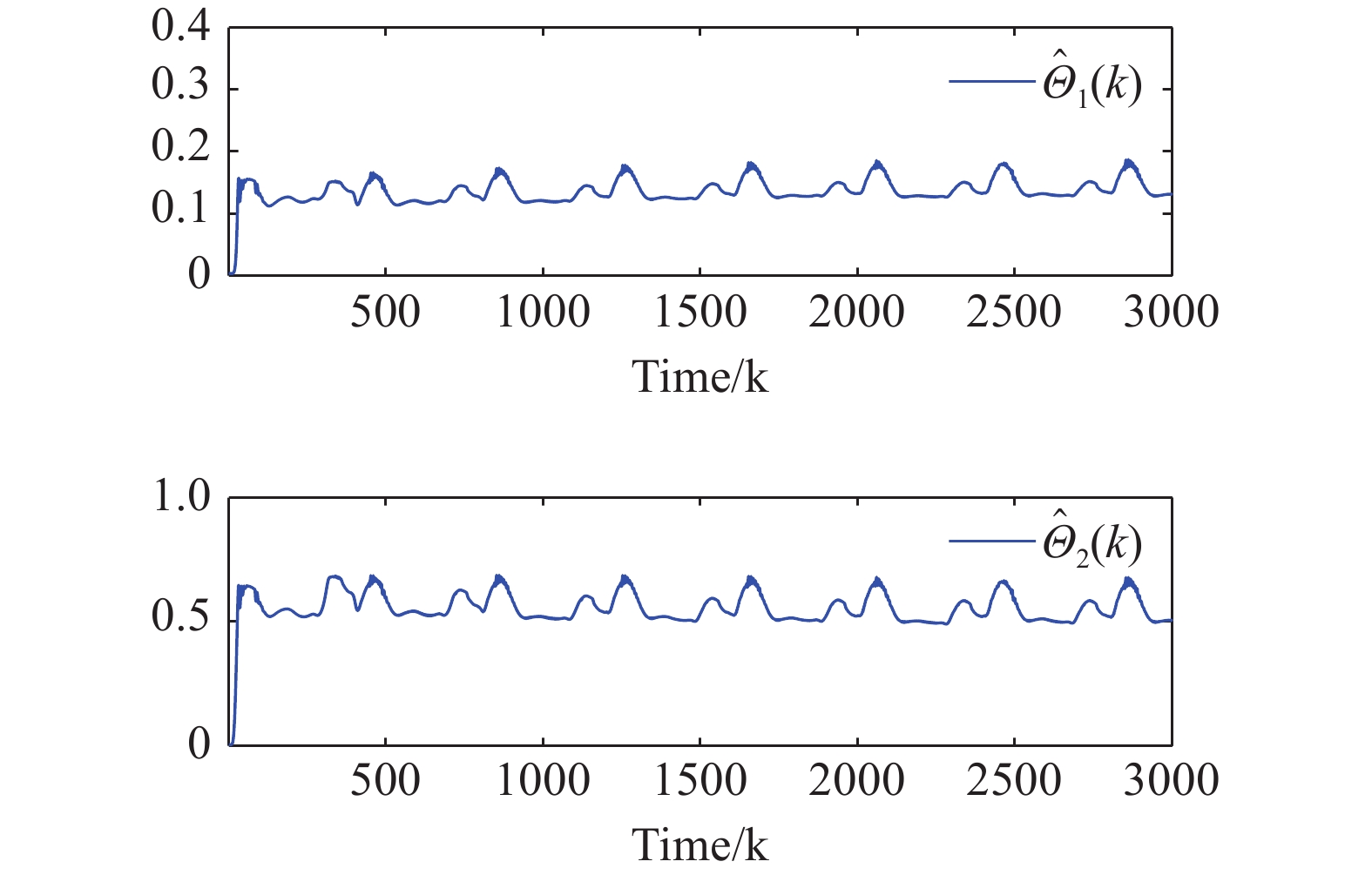
Figure 6. The 2-norms of the state observer NN weights.
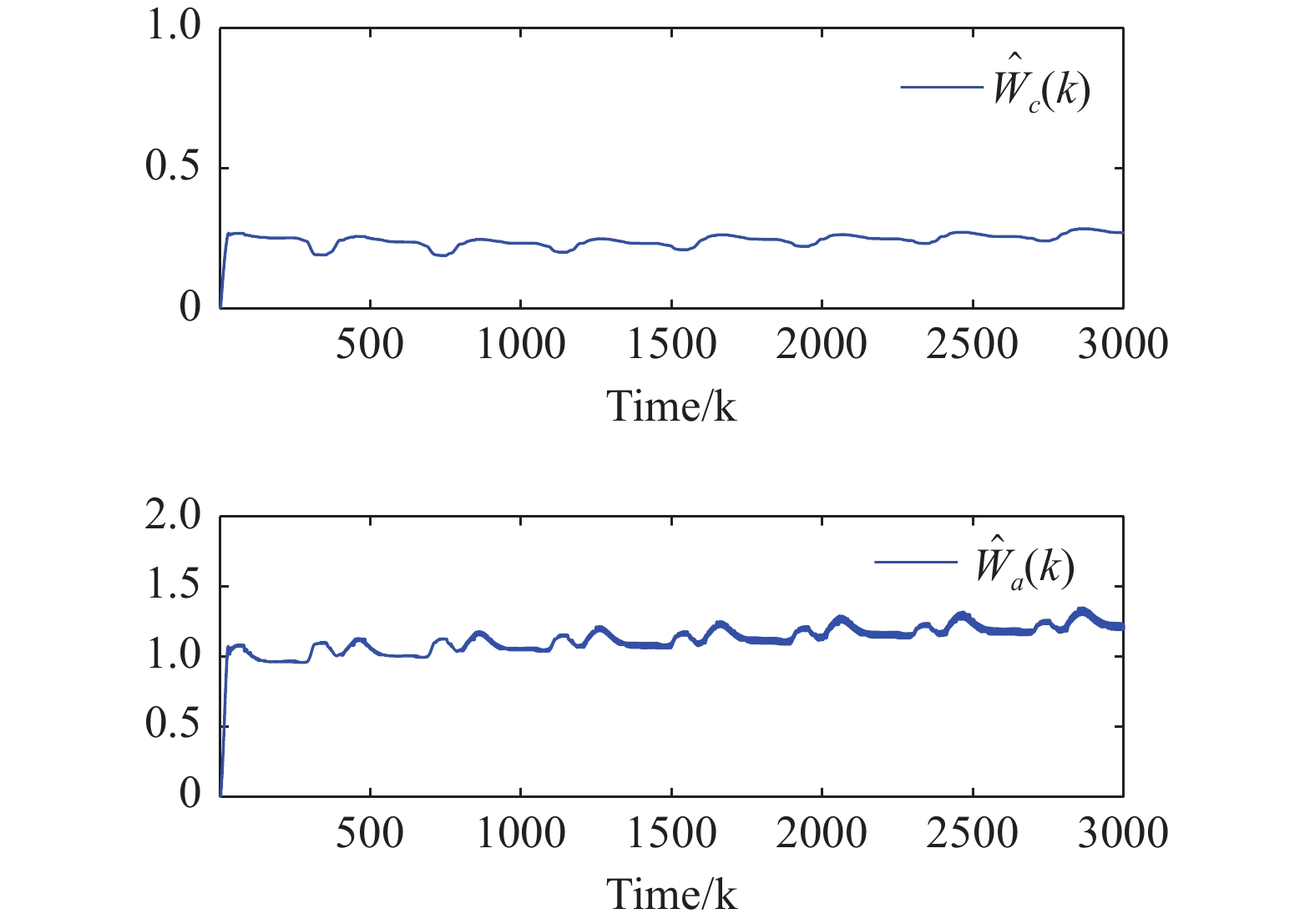
Figure 7. The 2-norms of the critic NN weights and the action NN weights.
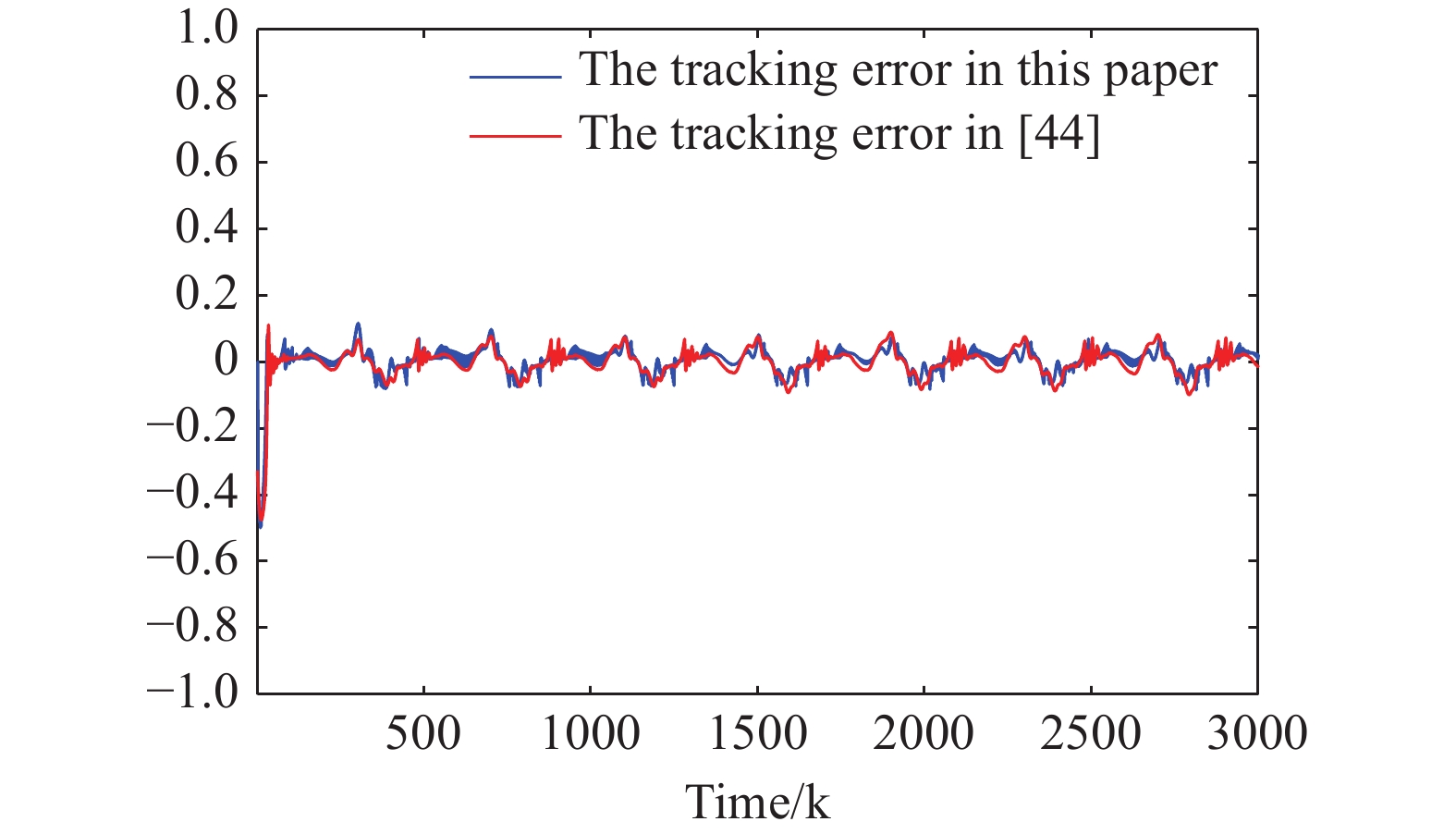
Figure 8. The tracking errors presented in this paper and in [44].
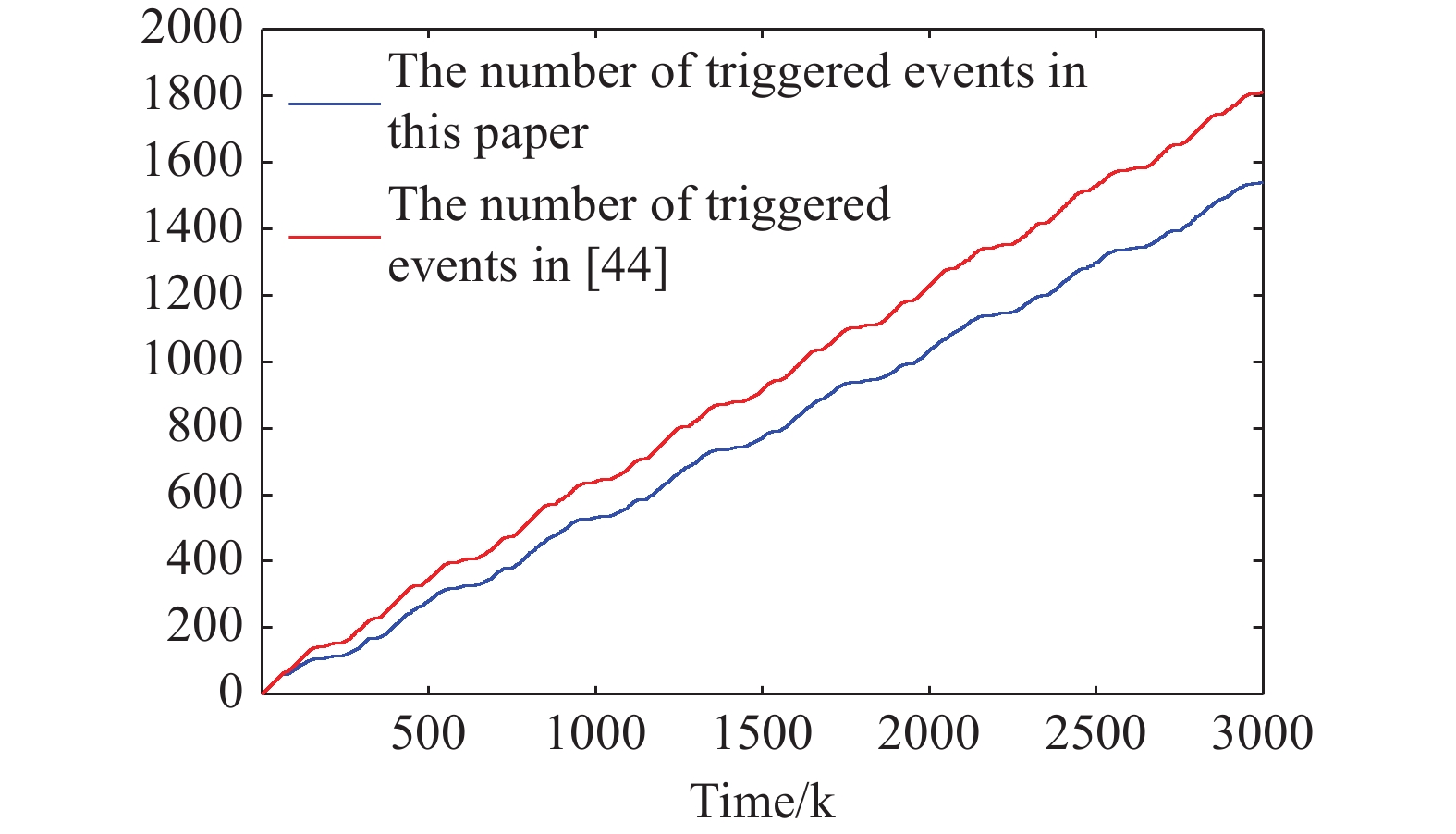
Figure 9. The number of triggered events presented in this paper and in [44].
Furthermore, we compare the developed ET output-feedback optimal tracking control scheme with the traditional ET adaptive neural network tracking control scheme presented in [44]. Figure 8 and Figure 9 display the tracking errors and the number of triggered events presented in this paper and in [44]. According to Table 1, the proposed ET output-feedback optimal tracking control method in this paper obtains smaller mean square tracking errors (MSTE) and fewer triggered events. The simulation results demonstrate the effectiveness of the proposed control scheme.
| Simulation comparisons | MSTE | Trigger rate |
| The ET optimal tracking controller | 0.0022 | 51.2% |
| The ET Adaptive NN tracking controller | 0.0028 | 60.4% |
7. Conclusion
In this paper, a novel ET output-feedback optimal tracking control scheme has been developed for a class of uncertain DTPFN systems. The neural state observer has been constructed to estimate the immeasurable system states in real time. In order to overcome the causal contradiction difficulty, the variable substitution approach has been applied to design the tracking controller, which prevents the n-step time delays caused by the traditional n-step-ahead prediction method. Under the ACD framework, the critic NN and the action NN have been constructed to design the optimal tracking controller. The action NN weight updating law has been designed based on the variable substitution approach, which guarantees the optimal tracking control performance. To save communication network resources between the sensor and the controller, a novel ET condition has been developed. According to the Lyapunov stability analysis, all the closed-loop system signals have proven to be UUB. Numerical simulation results have been represented to verify the effectiveness of the proposed method. In the future, it is expected to extend the control scheme proposed in this paper for DTPFN systems with other phenomena, such as state constraints [55] and actuator faults [56]. Additionally, the learning and optimal control of DTPFN systems constitutes another interesting topic [57].
Author Contributions: Conceptualization, Min Wang and Wei Wang: methodology; Min Wang: software; WeiWang: validation; Min Wang and Wei Wang: formal analysis; Wei Wang: investigation; Wei Wang: resources; Min Wang: writing—original draft preparation; Wei Wang: writing—review and editing; Min Wang: visual-ization; Min Wang: supervision; Min Wang: project administration; Min Wang: funding acquisition; Min Wang: All authors have read and agreed to the published version of the manuscript.
Funding: This work was supported in part by the National Natural Science Foundation of China under Grant62273156, and the Guangdong Natural Science Foundation under Grant 2019B151502058.
Data Availability Statement: Not applicable.
Conflicts of Interest: The authors declare no conflict of interest.
Acknowledgments: We would like to express our gratitude to the editor and anonymous reviewers for the improve-ment of this paper.

References
- Ferrara, A.; Giacomini, L. Control of a class of mechanical systems with uncertainties via a constructive adaptive/second order VSC approach. J. Dyn. Syst. Meas. Control, 2000, 122: 33−39. doi: 10.1115/1.482426
- Dai, S.L.; He, S.D.; Ma, Y.F.; et al. Cooperative learning-based formation control of autonomous marine surface vessels with prescribed performance. IEEE Trans. Syst. Man Cybern. Syst., 2022, 52: 2565−2577. doi: 10.1109/TSMC.2021.3051335
- Shao, S.Y.; Chen, M.; Zhang, Y.M. Adaptive discrete-time flight control using disturbance observer and neural networks. IEEE Trans. Neural Netw. Learn. Syst., 2019, 30: 3708−3721. doi: 10.1109/TNNLS.2019.2893643
- Shi, H.T.; Wang, M.; Wang, C. Pattern-based autonomous smooth switching control for constrained flexible joint manipulator. Neurocomputing, 2022, 492: 162−173. doi: 10.1016/j.neucom.2022.04.031
- Wang, M.; Wang, C. Learning from adaptive neural dynamic surface control of strict-feedback systems. IEEE Trans. Neural Netw. Learn. Syst., 2015, 26: 1247−1259. doi: 10.1109/TNNLS.2014.2335749
- Huang, L.W.; Wang, M. Filter-based event-triggered adaptive fuzzy control for discrete-time MIMO nonlinear systems with unknown control gains. IEEE Trans. Fuzzy Syst., 2022, 30: 3673−3684. doi: 10.1109/TFUZZ.2021.3122231
- Zhang, T.P.; Xia, M.Z.; Yi, Y. Adaptive neural dynamic surface control of strict-feedback nonlinear systems with full state constraints and unmodeled dynamics. Automatica, 2017, 81: 232−239. doi: 10.1016/j.automatica.2017.03.033
- Wang, M.; Huang, L.W.; Yang, C.G. NN-based adaptive tracking control of discrete-time nonlinear systems with actuator saturation and event-triggering protocol. IEEE Trans. Syst. Man Cybern. Syst., 2021, 51: 7613−7621. doi: 10.1109/TSMC.2020.2981954
- Wang, Z.S.; Liu, L.; Wu, Y.M.; et al. Optimal fault-tolerant control for discrete-time nonlinear strict-feedback systems based on adaptive critic design. IEEE Trans. Neural Netw. Learn. Syst., 2018, 29: 2179−2191. doi: 10.1109/TNNLS.2018.2810138
- Sui, S.; Chen, C.L.P.; Tong, S.C. A novel adaptive NN prescribed performance control for stochastic nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst., 2021, 32: 3196−3205. doi: 10.1109/TNNLS.2020.3010333
- Ge, S.S.; Wang, C. Adaptive NN control of uncertain nonlinear pure-feedback systems. Automatica, 2002, 38: 671−682. doi: 10.1016/S0005-1098(01)00254-0
- Wang, Z.S.; Liu, L.; Zhang, H.G. Neural network-based model-free adaptive fault-tolerant control for discrete-time nonlinear systems with sensor fault. IEEE Trans. Syst. Man Cybern. Syst., 2017, 47: 2351−2362. doi: 10.1109/TSMC.2017.2672664
- Chen, F.C.; Khalil, H.K. Adaptive control of a class of nonlinear discrete-time systems using neural networks. IEEE Trans. Autom. Control, 1995, 40: 791−801. doi: 10.1109/9.384214
- Ge, S.S.; Li, G.Y.; Lee, T.H. Adaptive NN control for a class of strict-feedback discrete-time nonlinear systems. Automatica, 2003, 39: 807−819. doi: 10.1016/S0005-1098(03)00032-3
- Ge, S.S.; Yang, C.G.; Lee, T.H. Adaptive predictive control using neural network for a class of pure-feedback systems in discrete time. IEEE Trans. Neural Netw., 2008, 19: 1599−1614. doi: 10.1109/TNN.2008.2000446
- Li, S.; Li, D.P.; Liu, Y.J. Adaptive neural network tracking design for a class of uncertain nonlinear discrete-time systems with unknown time-delay. Neurocomputing, 2015, 168: 152−159. doi: 10.1016/j.neucom.2015.06.003
- Wang, M.; Shi, H.T.; Wang, C.; et al. Dynamic learning from adaptive neural control for discrete-time strict-feedback systems. IEEE Trans. Neural Netw. Learn. Syst., 2022, 33: 3700−3712. doi: 10.1109/TNNLS.2021.3054378
- Li, Y.N.; Yang, C.G.; Ge, S.S.;
et al . Adaptive output feedback NN control of a class of discrete-time MIMO nonlinear systems with unknown control directions.IEEE Trans. Syst. Man Cybern. Part B Cybern .2011 ,41 , 507–517. doi:10.1109/TSMCB.2010.2065223 - Wang, M.; Wang, Z.D.; Dong, H.L.; et al. A novel framework for backstepping-based control of discrete-time strict-feedback nonlinear systems with multiplicative noises. IEEE Trans. Autom. Control, 2021, 66: 1484−1496. doi: 10.1109/TAC.2020.2995576
- Wang, W.; Wang, M.; Dai, S.L. Adaptive neural event-triggered optimal tracking control for discrete-time pure-feedback systems. In
Proceedings of the 2023 42nd Chinese Control Conference (CCC ),Tianjin, 24–26 July 2023 ; IEEE: New York, 2023; pp. 2335–2340. doi: 10.23919/CCC58697.2023.10240434 - Hu, J.; Zhang, H.X.; Liu, H.J.; et al. A survey on sliding mode control for networked control systems. Int. J. Syst. Sci., 2021, 52: 1129−1147. doi: 10.1080/00207721.2021.1885082
- Wang, X.L.; Sun, Y.; Ding, D.R. Adaptive dynamic programming for networked control systems under communication constraints: A survey of trends and techniques. Int. J. Netw. Dyn. Intell., 2022, 1: 85−98. doi: 10.53941/ijndi0101008
- Wang, Y.; Liu, H.J.; Tan, H.L. An overview of filtering for sampled-data systems under communication constraints. Int. J. Netw. Dyn. Intell., 2023, 2: 100011. doi: 10.53941/ijndi.2023.100011
- Wang, Y.A.; Shen, B.; Zou, L.; et al. A survey on recent advances in distributed filtering over sensor networks subject to communication constraints. Int. J. Netw. Dyn. Intell., 2023, 2: 100007. doi: 10.53941/ijndi0201007
- Xu, B.; Hu, J.; Jia, C.Q.; et al. State estimation via prediction-based scheme for linear time-varying uncertain networks with communication transmission delays and stochastic coupling. Syst. Sci. Control Eng., 2021, 9: 173−187. doi: 10.1080/21642583.2021.1888820
- Saif, M.; Liu, B.; Fan, H.J. Stabilisation and control of a class of discrete-time nonlinear stochastic output-dependent system with random missing measurements. Int. J. Control, 2017, 90: 1678−1687. doi: 10.1080/00207179.2016.1219066
- Liu, A.D.; Zhang, W.A.; Yu, L.; et al. New results on stabilization of networked control systems with packet disordering. Automatica, 2015, 52: 255−259. doi: 10.1016/j.automatica.2014.12.006
- Tao, H.M.; Tan, H.L.; Chen, Q. W.; et al. H∞ state estimation for memristive neural networks with randomly occurring DoS attacks. Syst. Sci. Control Eng., 2022, 10: 154−165. doi: 10.1080/21642583.2022.2048322
- Sun, Y.; Tian, X.; Wei, G.L. Finite-time distributed resilient state estimation subject to hybrid cyber-attacks: A new dynamic event-triggered case. Int. J. Syst. Sci., 2022, 53: 2832−2844. doi: 10.1080/00207721.2022.2083256
- Tabuada, P. Event-triggered real-time scheduling of stabilizing control tasks. IEEE Trans. Autom. Control, 2007, 52: 1680−1685. doi: 10.1109/TAC.2007.904277
- Li, Y.X.; Yang, G.H. Adaptive neural control of pure-feedback nonlinear systems with event-triggered communications. IEEE Trans. Neural Netw. Learn. Syst., 2018, 29: 6242−6251. doi: 10.1109/TNNLS.2018.2828140
- Jin, X.; Li, Y.X.; Tong, S.C. Adaptive event-triggered control design for nonlinear systems with full state constraints. IEEE Trans. Fuzzy Syst., 2021, 29: 3803−3811. doi: 10.1109/TFUZZ.2020.3028645
- Li, Y.X.; Yang, G.H. Model-based adaptive event-triggered control of strict-feedback nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst., 2018, 29: 1033−1045. doi: 10.1109/TNNLS.2017.2650238
- Guo, X.X.; Yan, W.S.; Cui, R.X. Event-triggered reinforcement learning-based adaptive tracking control for completely unknown continuous-time nonlinear systems. IEEE Trans. Cybern., 2020, 50: 3231−3242. doi: 10.1109/TCYB.2019.2903108
- Wang, W.; Li, Y.M. Observer-based event-triggered adaptive fuzzy control for leader-following consensus of nonlinear strict-feedback systems. IEEE Trans. Cybern., 2021, 51: 2131−2141. doi: 10.1109/TCYB.2019.2951151
- Li, W.; Liu, Y.G.; Cao, Z.R. Event-triggered sliding mode control for multi-agent systems subject to channel fading. Int. J. Syst. Sci., 2022, 53: 1233−1244. doi: 10.1080/00207721.2021.1995527
- Li, Y.X.; Yang, G.H. Event-based adaptive NN tracking control of nonlinear discrete-time systems. IEEE Trans. Neural Netw. Learn. Syst., 2018, 29: 4359−4369. doi: 10.1109/TNNLS.2017.2765683
- Wang, M.; Ou, F.H.; Shi, H.T.; et al. Model-based adaptive event-triggered tracking control of discrete-time nonlinear systems subject to strict-feedback form. IEEE Trans. Syst. Man Cybern. Syst., 2022, 52: 4557−4568. doi: 10.1109/TSMC.2021.3098025
- Xu, W.Q.; Liu, X.P.; Wang, H.Q.; et al. Event-based adaptive NN controller design for strict-feedback discrete-time nonlinear systems with input dead zone and saturation. Int. J. Control, 2022, 95: 218−233. doi: 10.1080/00207179.2020.1788727
- Wang, M.; Wang, Z.D.; Chen, Y.; et al. Adaptive neural event-triggered control for discrete-time strict-feedback nonlinear systems. IEEE Trans. Cybern., 2020, 50: 2946−2958. doi: 10.1109/TCYB.2019.2921733
- Dong, C.; Ye, Q.Z.; Dai, S.L. Neural-network-based adaptive output-feedback formation tracking control of USVs under collision avoidance and connectivity maintenance constraints. Neurocomputing, 2020, 401: 101−112. doi: 10.1016/j.neucom.2020.03.033
- Hassan, M.F.; Hammuda, M. Leader-follower formation control of mobile nonholonomic robots via a new observer-based controller. Int. J. Syst. Sci., 2020, 51: 1243−1265. doi: 10.1080/00207721.2020.1758233
- Su, Y.F.; Cai, H.; Huang, J. The cooperative output regulation by the distributed observer approach. Int. J. Netw. Dyn. Intell., 2022, 1: 20−35. doi: 10.53941/ijndi0101003
- Wang, M.; Huang, L.W.; Zhao, Z.J.; et al. Observer-based adaptive neural output-feedback event-triggered control for discrete-time nonlinear systems using variable substitution. Int. J. Robust Nonlinear Control, 2021, 31: 5541−5562. doi: 10.1002/rnc.5530
- Wang, M.; Wang, K.N.; Huang, L.W.; et al. Observer-based event-triggered tracking control for discrete-time nonlinear systems using adaptive critic design. IEEE Trans. Syst. Man Cybern. Syst., 2023, 53: 5393−5403. doi: 10.1109/TSMC.2023.3269108
- Wang, D. Research progress on learning-based robust adaptive critic control.
Acta Autom. Sin .2019 ,45 , 1031–1043 (in Chinese). doi: 10.16383/j.aas.c170701 - Werbos, P.J. Approximate dynamic programming for real-time control and neural modeling. In
Proceedings of Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches, New York ; Van Nostrand Reinhold, 1992. - Wang, D.; Liu, D.R.; Wei, Q.L.; et al. Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming. Automatica, 2012, 48: 1825−1832. doi: 10.1016/j.automatica.2012.05.049
- Dong, L.; Zhong, X.N.; Sun, C.Y.; et al. Adaptive event-triggered control based on heuristic dynamic programming for nonlinear discrete-time systems. IEEE Trans. Neural Netw. Learn. Syst., 2017, 28: 1594−1605. doi: 10.1109/TNNLS.2016.2541020
- Wen, G.X.; Niu, B. Optimized tracking control based on reinforcement learning for a class of high-order unknown nonlinear dynamic systems. Inf. Sci., 2022, 606: 368−379. doi: 10.1016/j.ins.2022.05.048
- Li, Y.M.; Fan, Y.L.; Li, K.W.; et al. Adaptive optimized backstepping control-based RL algorithm for stochastic nonlinear systems with state constraints and its application. IEEE Trans. Cybern., 2022, 52: 10542−10555. doi: 10.1109/TCYB.2021.3069587
- Liu, Y.J.; Gao, Y.; Tong, S.C.; et al. Fuzzy approximation-based adaptive backstepping optimal control for a class of nonlinear discrete-time systems with dead-zone. IEEE Trans. Fuzzy Syst., 2016, 24: 16−28. doi: 10.1109/TFUZZ.2015.2418000
- Li, H.Y.; Wu, Y.; Chen, M. Adaptive fault-tolerant tracking control for discrete-time multiagent systems via reinforcement learning algorithm. IEEE Trans. Cybern., 2021, 51: 1163−1174. doi: 10.1109/TCYB.2020.2982168
- Tang, L.; Liu, Y.J.; Chen, C.L.P. Adaptive critic design for pure-Feedback discrete-time MIMO systems preceded by unknown backlashlike hysteresis. IEEE Trans. Neural Netw. Learn. Syst., 2018, 29: 5681−5690. doi: 10.1109/TNNLS.2018.2805689
- Wang, M.; Wang, L.X.; Yang, C.G. Sliding mode differentiator-based event-triggered control for state-constrained nonlinear systems with unknown virtual control coefficients. Int. J. Control, 2023, 96: 599−613. doi: 10.1080/00207179.2021.2005828
- Deng, C.; Wen, C.Y. Distributed resilient observer-based fault-tolerant control for heterogeneous multiagent systems under actuator faults and DOS attacks. IEEE Trans. Control Netw. Syst., 2020, 7: 1308−1318. doi: 10.1109/TCNS.2020.2972601
- Wang, M.; Shi, H.T.; Wang, C.; et al. Neural learning control for discrete-time nonlinear systems in pure-feedback form. Sci. China Inf. Sci., 2022, 65: 122206. doi: 10.1007/s11432-020-3138-7


