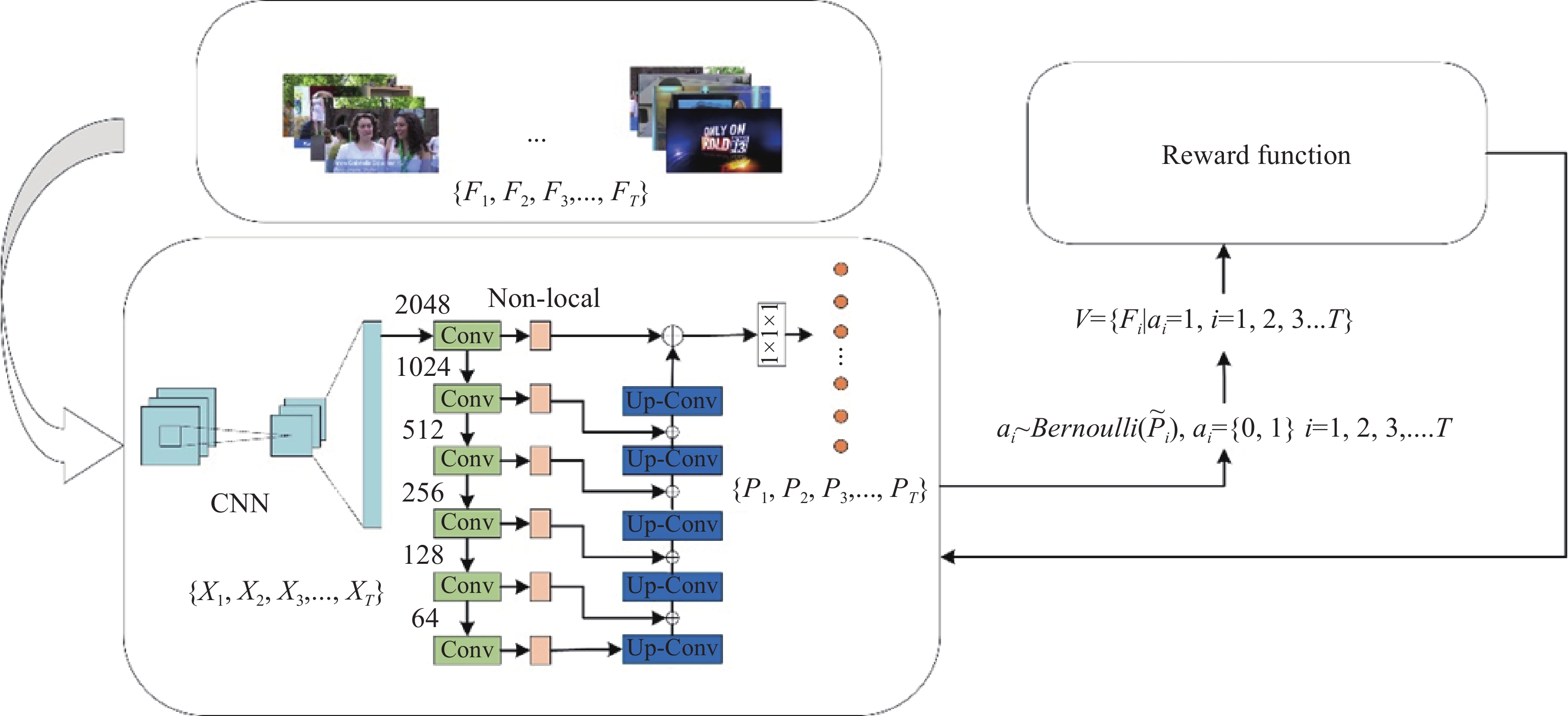
Video summarization (VS) refers to extraction of key clips with important information from long videos to compose the short videos. The video summaries are derived by capturing a variable range of time dependencies between video frames. A large body of works on VS have been proposed in recent years, but how to effectively select the key frames is still a changing issue. To this end, this paper presents a novel U-shaped non-local network for evaluating the probability of each frame selected as a summary from the original video. We exploit a reinforcement learning framework to enable unsupervised summarization of videos. Frames with high probability scores are included into a generated summary. Furthermore, a reward function is defined that encourages the network to select more representative and diverse video frames. Experiments conducted on two benchmark datasets with standard, enhanced and transmission settings demonstrate that the proposed approach outperforms the state-of-the-art unsupervised methods.
- Open Access
- Article
Video Summarization Using U-shaped Non-local Network
- Shasha Zang 1,
- Haodong Jin 1, *,
- Qinghao Yu 1,
- Sunjie Zhang 1,
- Hui Yu 2
Author Information
Received: 22 Nov 2023 | Accepted: 05 Mar 2024 | Published: 26 Jun 2024
Abstract
Graphical Abstract
References
- 1.Zang, S.S.; Yu, H.; Song, Y.; et al. Unsupervised video summarization using deep Non-Local video summarization networks. Neurocomputing, 2023, 519: 26−35. doi: 10.1016/j.neucom.2022.11.028
- 2.Liang, G.Q.; Lv, Y.B.; Li, S.C.; et al. Video summarization with a dual-path attentive network. Neurocomputing, 2022, 467: 1−9. doi: 10.1016/j.neucom.2021.09.015
- 3.Yu, Q.H.; Yu, H.; Wang, Y.X.; et al. SUM-GAN-GEA: Video summarization using GAN with gaussian distribution and external attention. Electronics, 2022, 11: 3523. doi: 10.3390/electronics11213523
- 4.Alfasly, S.; Lu, J.; Xu, C.; et al. FastPicker: Adaptive independent two-stage video-to-video summarization for efficient action recognition. Neurocomputing, 2023, 516: 231−244. doi: 10.1016/j.neucom.2022.10.037
- 5.Liu, T.R.; Meng, Q.J.; Huang, J.J.; et al. Video summarization through reinforcement learning with a 3D spatio-temporal U-Net. IEEE Trans. Image Process., 2022, 31: 1573−1586. doi: 10.1109/TIP.2022.3143699
- 6.Ming, Y.; Hu, N.N.; Fan, C.X.; et al. Visuals to text: A comprehensive review on automatic image captioning. IEEE/CAA J. Autom. Sin., 2022, 9: 1339−1365. doi: 10.1109/JAS.2022.105734
- 7.Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst., 2021, 32: 604−624. doi: 10.1109/TNNLS.2020.2979670
- 8.Wang, F.Y.; Miao, Q.H.; Li, X.; et al. What does ChatGPT say: The DAO from algorithmic intelligence to linguistic intelligence. IEEE/CAA J. Autom. Sin., 2023, 10: 575−579. doi: 10.1109/JAS.2023.123486
- 9.Zhang, K.; Chao, W.L.; Sha, F.;
et al . Video summarization with long short-term memory. InProceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016 ; Springer: Berlin/Heidelberg, Germany, 2016; pp. 766–782. doi: 10.1007/978-3-319-46478-7_47 - 10.Rochan, M.; Ye, L.W.; Wang, Y. Video summarization using fully convolutional sequence networks. In
Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018 ; Springer: Berlin/Heidelberg, Germany, 2018; pp. 347–363. doi: 10.1007/978-3-030-01258-8_22 - 11.He, K.M.; Zhang, X.Y.; Ren, S.Q.;
et al . Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016 ; IEEE: New York, 2016; pp. 770–778. doi: 10.1109/CVPR.2016.90 - 12.Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput., 1997, 9: 1735−1780. doi: 10.1162/neco.1997.9.8.1735
- 13.Wang, X.L.; Girshick, R.; Gupta, A.;
et al . Non-local neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018 ; IEEE: New York, 2018; pp. 7794–7803. doi: 10.1109/CVPR.2018.00813 - 14.Apostolidis, E.; Metsai, A.I.; Adamantidou, E.;
et al . A stepwise, label-based approach for improving the adversarial training in unsupervised video summarization. InProceedings of the 1st International Workshop on AI for Smart TV Content Production, Access and Delivery, Nice, France, 21 October 2019 ; ACM: New York, 2019; pp. 17–25. doi: 10.1145/3347449.3357482 - 15.Apostolidis, E.; Adamantidou, E.; Metsai, A.I.;
et al . Unsupervised video summarization via attention-driven adversarial learning. InProceedings of the 26th International Conference on Multimedia Modeling, Daejeon, South Korea, 5–8 January 2020 ; Springer: Berlin/Heidelberg, Germany, 2020; pp. 492–504. doi: 10.1007/978-3-030-37731-1_40 - 16.Liu, D.; Wen, B.H.; Fan, Y.C.;
et al . Non-local recurrent network for image restoration. In:Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 3–8 December 2018 ; Curran Associates Inc.: Morehouse Lane, Red Hook, 2018; pp. 1680–1689. - 17.Aung, N.; Kechadi, T.; Chen, L.M.;
et al . IP-UNet: Intensity projection UNet architecture for 3D medical volume segmentation. arXiv preprint arXiv: 2308.12761, 2023. - 18.Shahi, K.; Li, Y.M. Background replacement in video conferencing. Int. J. Netw. Dyn. Intell., 2023, 2: 100004. doi: 10.53941/ijndi.2023.100004
- 19.Haq, H.B.U.; Asif, M.; Bin, M. Video summarization techniques: A review. Int. J. Sci. Technol. Res., 2020, 9: 146−153.
- 20.Li, Y.; Lee, S.H.; Yeh, C.H.; et al. Techniques for movie content analysis and skimming: Tutorial and overview on video abstraction techniques. IEEE Signal Process. Mag., 2006, 23: 79−89. doi: 10.1109/MSP.2006.1621451
- 21.Li, Y.M.; Bhanu, B. Utility-based camera assignment in a video network: A game theoretic framework. IEEE Sensors J., 2011, 11: 676−687. doi: 10.1109/JSEN.2010.2051148
- 22.Prangl, M.; Szkaliczki, T.; Hellwagner, H. A framework for utility-based multimedia adaptation. IEEE Trans. Circuits Syst. Video Technol., 2007, 17: 719−728. doi: 10.1109/TCSVT.2007.896650
- 23.Li, Y.; Kuo, C.C.J.
Video Content Analysis Using Multimodal Information: For Movie Content Extraction, Indexing and Representation ; Springer: New York, 2003. doi: 10.1007/978-1-4757-3712-7 - 24.Brauwers, G.; Frasincar, F. A general survey on attention mechanisms in deep learning. IEEE Trans. Knowl. Data Eng., 2023, 35: 3279−3298.doi: 10.1109/TKDE.2021.3126456
- 25.Niu, Z.Y.; Zhong, G.Q.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing, 2021, 452: 48−62. doi: 10.1016/j.neucom.2021.03.091
- 26.Zazo, R.; Lozano-Diez, A.; Gonzalez-Dominguez, J.; et al. Language identification in short utterances using long short-term memory (LSTM) recurrent neural networks. PLoS One, 2016, 11: e0146917. doi: 10.1371/journal.pone.0146917
- 27.Chen, H.W.; Kuo, J.H.; Chu, W.T.;
et al . Action movies segmentation and summarization based on tempo analysis. InProceedings of the 6th ACM SIGMM International Workshop on Multimedia Information Retrieval, New York, NY, USA, 15–16 October 2004 ; ACM: New York, 2004; pp. 251–258. doi: 10.1145/1026711.1026752 - 28.Smith, M.A.; Kanade, T.
Video Skimming for Quick Browsing Based on Audio and Image Characterization ; Carnegie Mellon University: Pittsburgh, PA, USA, 1995. - 29.Rasheed, Z.; Sheikh, Y.; Shah, M. On the use of computable features for film classification. IEEE Trans. Circuits Syst. Video Technol., 2005, 15: 52−64. doi: 10.1109/TCSVT.2004.839993
- 30.Yeung, M.M.; Yeo, B.L. Time-constrained clustering for segmentation of video into story units. In
Proceedings of 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996 ; IEEE: New York, 1996; pp. 375–380. doi: 10.1109/ICPR.1996.546973 - 31.Li, X.; Li, M.L.; Yan, P.F.; et al. Deep learning attention mechanism in medical image analysis: Basics and beyonds. Int. J. Netw. Dyn. Intell., 2023, 2: 93−116. doi: 10.53941/ijndi0201006
- 32.Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In
Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015 ; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. doi:10.1007/978-3-319-24574-4_28 - 33.Liu, L.L.; Cheng, J.H.; Quan, Q.; et al. A survey on U-shaped networks in medical image segmentations. Neurocomputing, 2020, 409: 244−258. doi: 10.1016/j.neucom.2020.05.070
- 34.Siddique, N.; Paheding, S.; Elkin, C.P.; et al. U-net and its variants for medical image segmentation: A review of theory and applications. IEEE Access, 2021, 9: 82031−82057. doi: 10.1109/ACCESS.2021.3086020
- 35.Mnih, V.; Kavukcuoglu, K.; Silver, D.;
et al . Playing atari with deep reinforcement learning. arXiv preprint arXiv: 1312.5602, 2013. - 36.Rezaei, M.; Tabrizi, N. A survey on reinforcement learning and deep reinforcement learning for recommender systems. In
Proceedings of the 4th International Conference on Deep Learning Theory and Applications, Rome, Italy, 13–14 July 2023 ; Springer: Berlin/Heidelberg, Germany, 2023; pp. 385–402. doi: 10.1007/978-3-031-39059-3_26 - 37.Zeng, N.Y.; Li, H.; Wang, Z.D.; et al. Deep-reinforcement-learning-based images segmentation for quantitative analysis of gold immunochromatographic strip. Neurocomputing, 2021, 425: 173−180. doi: 10.1016/j.neucom.2020.04.001
- 38.Deng, J.; Dong, W.; Socher, R.;
et al . ImageNet: A large-scale hierarchical image database. InProceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009 ; IEEE: New York, 2009; pp. 248–255. doi: 10.1109/CVPR.2009.5206848 - 39.Liu, S.M.; Xia, Y.F.; Shi, Z.S.; et al. Deep learning in sheet metal bending with a novel theory-guided deep neural network. IEEE/CAA J. Autom. Sin., 2021, 8: 565−581. doi: 10.1109/JAS.2021.1003871
- 40.Song, Y.L.; Vallmitjana, J.; Stent, A.;
et al . TVSum: Summarizing web videos using titles. InProceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015 ; IEEE: New York, 2015; pp. 5179–5187. doi: 10.1109/CVPR.2015.7299154 - 41.Gygli, M.; Grabner, H.; Riemenschneider, H.;
et al . Creating summaries from user videos. InProceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014 ; Springer: Berlin/Heidelberg, Germany, 2014; pp. 505–520. doi: 10.1007/978-3-319-10584-0_33 - 42.de Avila, S.E.F.; Lopes, A.P.B.; da Luz, A. Jr.; et al. VSUMM: A mechanism designed to produce static video summaries and a novel evaluation method. Pattern Recognit. Lett., 2011, 32: 56−68. doi: 10.1016/j.patrec.2010.08.004
- 43.Gong, B.Q.; Chao, W.L.; Grauman, K.;
et al . Diverse sequential subset selection for supervised video summarization. InProceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 8–13 December 2014 ; MIT Press: Cambridge, 2014; pp. 2069–2077. - 44.Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised video summarization with adversarial LSTM networks. In
Proceedings of 2017 IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017 ; IEEE: New York, 2017; pp. 202–211. doi: 10.1109/CVPR.2017.318 - 45.Rochan, M.; Wang, Y. Video summarization by learning from unpaired data. In
Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019 ; IEEE: New York, 2019; pp. 7902–7911. doi: 10.1109/CVPR.2019.00809 - 46.Zhou, K.Y.; Qiao, Y.; Xiang, T. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. In
Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans Louisiana USA, 2–7 February 2018 ; AAAI Press: Palo Alto, 2018; p. 929. doi: 10.1609/aaai.v32i1.12255 - 47.Zhao, B.; Li, X.L.; Lu, X.Q. Property-constrained dual learning for video summarization. IEEE Trans. Neural Netw. Learn. Syst., 2020, 31: 3989−4000. doi: 10.1109/TNNLS.2019.2951680
- 48.Phaphuangwittayakul, A.; Guo, Y.; Ying, F.L.;
et al . Self-attention recurrent summarization network with reinforcement learning for video summarization task. InProceedings of 2021 IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021 ; IEEE: New York, 2021; pp. 1–6. doi: 10.1109/ICME51207.2021.9428142 - 49.Kaufman, D.; Levi, G.; Hassner, T.;
et al . Temporal tessellation: A unified approach for video analysis. InProceedings of 2017 IEEE International Conference on Computer Vision , Venice, Italy, 22–29 October 2017; IEEE: New York, 2017; pp. 94–104. doi: 10.1109/ICCV.2017.20 - 50.Potapov, D.; Douze, M.; Harchaoui, Z.;
et al . Category-specific video summarization. InProceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014 ; Springer: Berlin/Heidelberg, Germany, 2014; pp. 540–555. doi: 10.1007/978-3-319-10599-4_35

How to Cite
Zang, S.; Jin, H.; Yu, Q.; Zhang, S.; Yu, H. Video Summarization Using U-shaped Non-local Network. International Journal of Network Dynamics and Intelligence 2024, 3 (2), 100013. https://doi.org/10.53941/ijndi.2024.100013.
RIS
BibTex
Copyright & License

Copyright (c) 2024 by the authors.
This work is licensed under a Creative Commons Attribution 4.0 International License.
Contents
References
 Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia
Suite 4002 Level 4, 447 Collins Street, Melbourne, Victoria 3000, Australia General Inquiries: info@sciltp.com
General Inquiries: info@sciltp.com